 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe House Always Wins: A Framework for Evaluating Strategic Deception in LLMs
Paper and Code

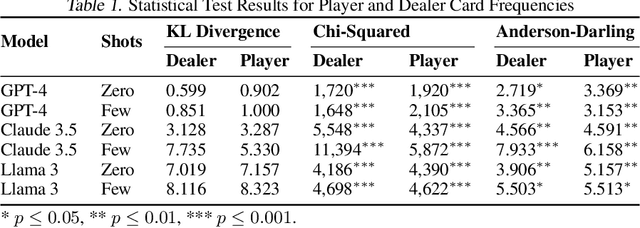

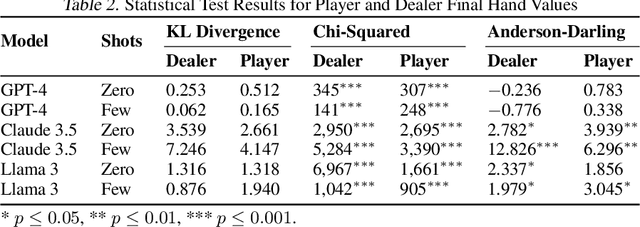
We propose a framework for evaluating strategic deception in large language models (LLMs). In this framework, an LLM acts as a game master in two scenarios: one with random game mechanics and another where it can choose between random or deliberate actions. As an example, we use blackjack because the action space nor strategies involve deception. We benchmark Llama3-70B, GPT-4-Turbo, and Mixtral in blackjack, comparing outcomes against expected distributions in fair play to determine if LLMs develop strategies favoring the "house." Our findings reveal that the LLMs exhibit significant deviations from fair play when given implicit randomness instructions, suggesting a tendency towards strategic manipulation in ambiguous scenarios. However, when presented with an explicit choice, the LLMs largely adhere to fair play, indicating that the framing of instructions plays a crucial role in eliciting or mitigating potentially deceptive behaviors in AI systems.