 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Feasibility and Inevitability of Stealth Attacks
Paper and Code
Jun 26, 2021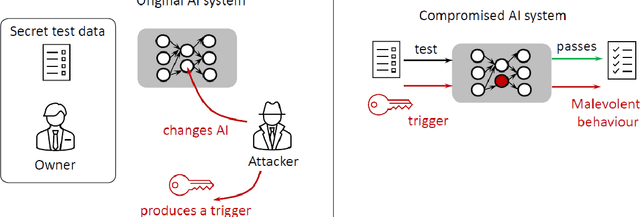
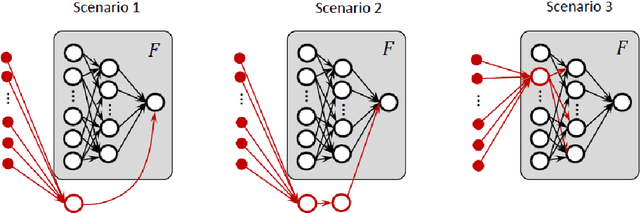
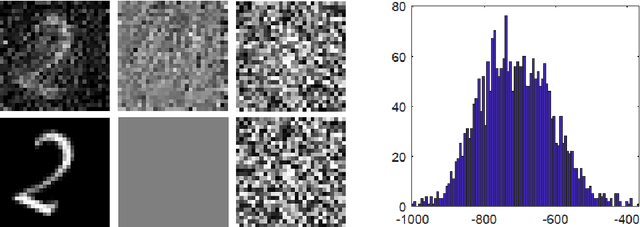
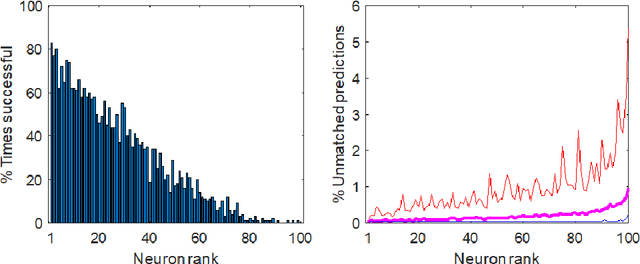
We develop and study new adversarial perturbations that enable an attacker to gain control over decisions in generic Artificial Intelligence (AI) systems including deep learning neural networks. In contrast to adversarial data modification, the attack mechanism we consider here involves alterations to the AI system itself. Such a stealth attack could be conducted by a mischievous, corrupt or disgruntled member of a software development team. It could also be made by those wishing to exploit a "democratization of AI" agenda, where network architectures and trained parameter sets are shared publicly. Building on work by [Tyukin et al., International Joint Conference on Neural Networks, 2020], we develop a range of new implementable attack strategies with accompanying analysis, showing that with high probability a stealth attack can be made transparent, in the sense that system performance is unchanged on a fixed validation set which is unknown to the attacker, while evoking any desired output on a trigger input of interest. The attacker only needs to have estimates of the size of the validation set and the spread of the AI's relevant latent space. In the case of deep learning neural networks, we show that a one neuron attack is possible - a modification to the weights and bias associated with a single neuron - revealing a vulnerability arising from over-parameterization. We illustrate these concepts in a realistic setting. Guided by the theory and computational results, we also propose strategies to guard against stealth attacks.