 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Familiarity Hypothesis: Explaining the Behavior of Deep Open Set Methods
Paper and Code
Mar 04, 2022
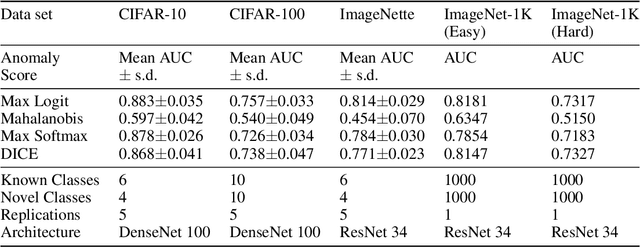
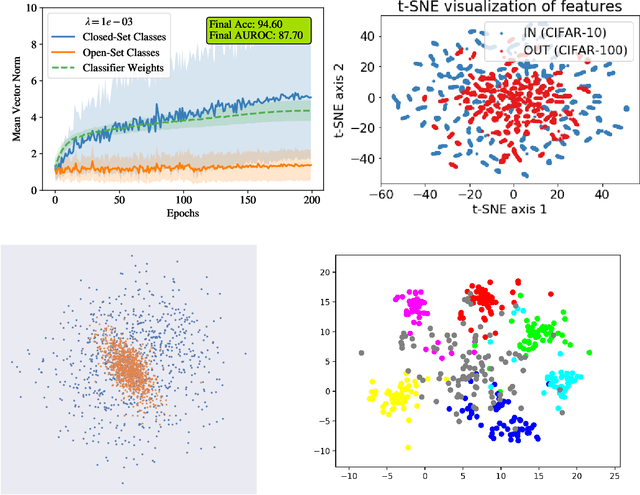
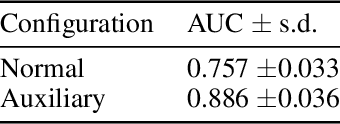
In many object recognition applications, the set of possible categories is an open set, and the deployed recognition system will encounter novel objects belonging to categories unseen during training. Detecting such "novel category" objects is usually formulated as an anomaly detection problem. Anomaly detection algorithms for feature-vector data identify anomalies as outliers, but outlier detection has not worked well in deep learning. Instead, methods based on the computed logits of visual object classifiers give state-of-the-art performance. This paper proposes the Familiarity Hypothesis that these methods succeed because they are detecting the absence of familiar learned features rather than the presence of novelty. The paper reviews evidence from the literature and presents additional evidence from our own experiments that provide strong support for this hypothesis. The paper concludes with a discussion of whether familiarity detection is an inevitable consequence of representation learning.