 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{ACCORD}$: Closing the Commonsense Measurability Gap
Paper and Code


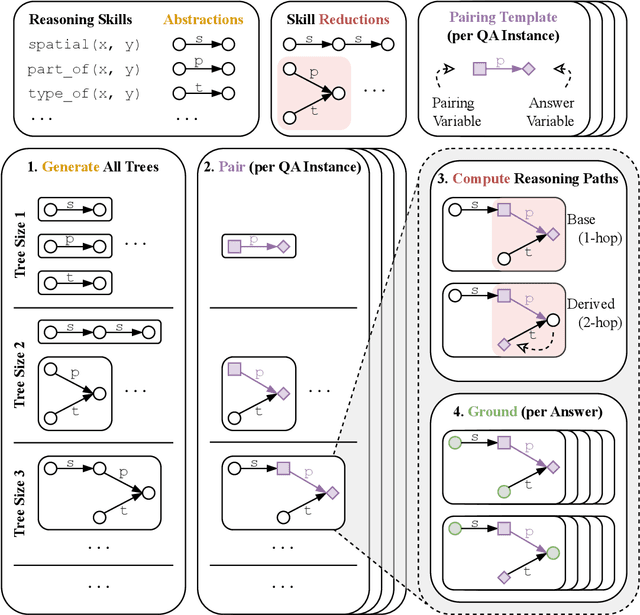

We present $\texttt{ACCORD}$, a framework and benchmark suite for disentangling the commonsense grounding and reasoning abilities of large language models (LLMs) through controlled, multi-hop counterfactuals. $\texttt{ACCORD}$ introduces formal elements to commonsense reasoning to explicitly control and quantify reasoning complexity beyond the typical 1 or 2 hops. Uniquely, $\texttt{ACCORD}$ can automatically generate benchmarks of arbitrary reasoning complexity, and so it scales with future LLM improvements. Benchmarking state-of-the-art LLMs -- including GPT-4o (2024-05-13), Llama-3-70B-Instruct, and Mixtral-8x22B-Instruct-v0.1 -- shows performance degrading to random chance with only moderate scaling, leaving substantial headroom for improvement. We release a leaderboard of the benchmark suite tested in this work, as well as code for automatically generating more complex benchmarks.