 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Training for Hyperspectral Image Super-resolution
Paper and Code
Sep 13, 2024
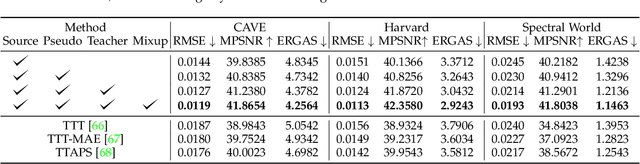

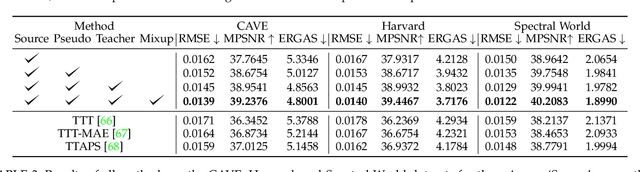
The progress on Hyperspectral image (HSI) super-resolution (SR) is still lagging behind the research of RGB image SR. HSIs usually have a high number of spectral bands, so accurately modeling spectral band interaction for HSI SR is hard. Also, training data for HSI SR is hard to obtain so the dataset is usually rather small. In this work, we propose a new test-time training method to tackle this problem. Specifically, a novel self-training framework is developed, where more accurate pseudo-labels and more accurate LR-HR relationships are generated so that the model can be further trained with them to improve performance. In order to better support our test-time training method, we also propose a new network architecture to learn HSI SR without modeling spectral band interaction and propose a new data augmentation method Spectral Mixup to increase the diversity of the training data at test time. We also collect a new HSI dataset with a diverse set of images of interesting objects ranging from food to vegetation, to materials, and to general scenes. Extensive experiments on multiple datasets show that our method can improve the performance of pre-trained models significantly after test-time training and outperform competing methods significantly for HSI SR.