 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Random Indexing of Context Vectors Applied to Event Detection
Paper and Code
Sep 30, 2020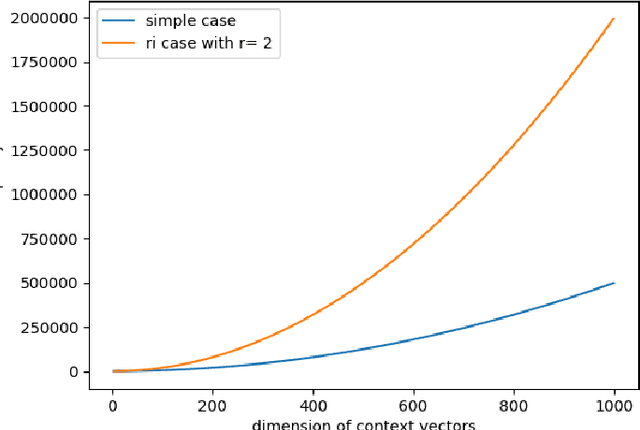

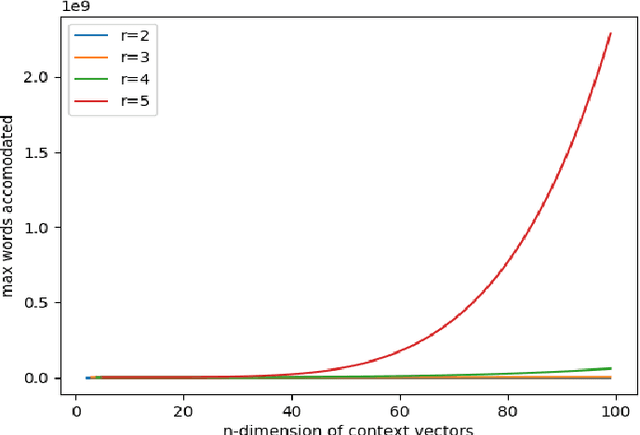

In this paper we explore new representations for encoding language data. The general method of one-hot encoding grows linearly with the size of the word corpus in space-complexity. We address this by using Random Indexing(RI) of context vectors with non-zero entries. We propose a novel RI representation where we exploit the effect imposing a probability distribution on the number of randomized entries which leads to a class of RI representations. We also propose an algorithm that is log linear in the size of word corpus to track the semantic relationship of the query word to other words for suggesting the events that are relevant to the word in question. Finally we run simulations on the novel RI representations using the proposed algorithms for tweets relevant to the word "iPhone" and present results. The RI representation is shown to be faster and space efficient as compared to BoW embeddings.