 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemplate co-updating in multi-modal human activity recognition systems
Paper and Code
Dec 04, 2019
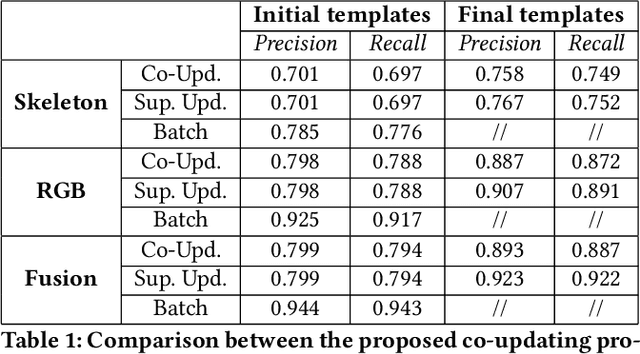
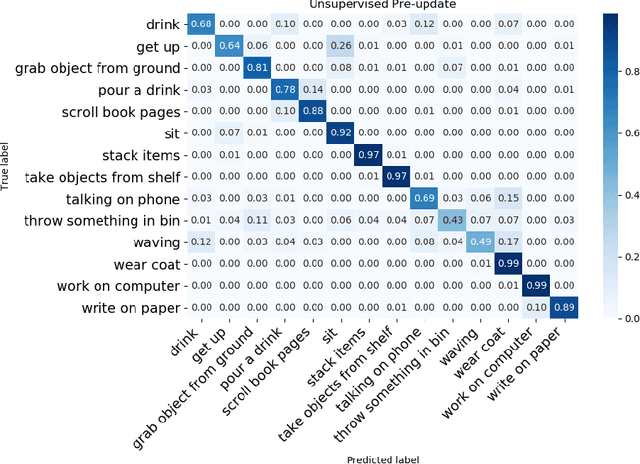

Multi-modal systems are quite common in the context of human activity recognition; widely used RGB-D sensors (Kinect is the most prominent example) give access to parallel data streams, typically RGB images, depth data, skeleton information. The richness of multimodal information has been largely exploited in many works in the literature, while an analysis of their effectiveness for incremental template updating has not been investigated so far. This paper is aimed at defining a general framework for unsupervised template updating in multi-modal systems, where the different data sources can provide complementary information, increasing the effectiveness of the updating procedure and reducing at the same time the probability of incorrect template modifications.