 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report: Assisting Backdoor Federated Learning with Whole Population Knowledge Alignment
Paper and Code
Jul 25, 2022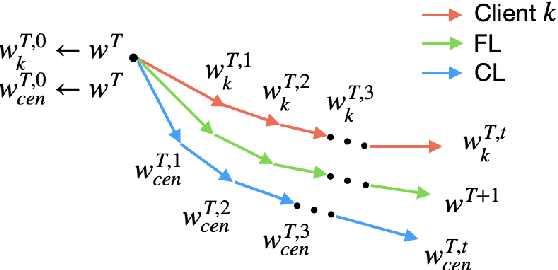

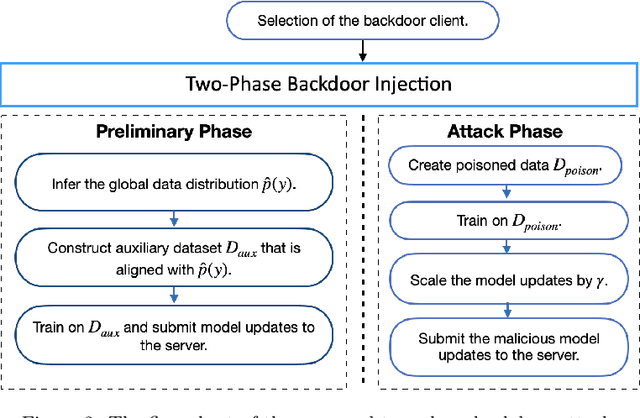
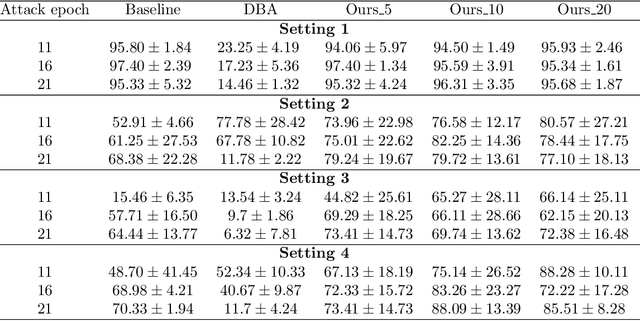
Due to the distributed nature of Federated Learning (FL), researchers have uncovered that FL is vulnerable to backdoor attacks, which aim at injecting a sub-task into the FL without corrupting the performance of the main task. Single-shot backdoor attack achieves high accuracy on both the main task and backdoor sub-task when injected at the FL model convergence. However, the early-injected single-shot backdoor attack is ineffective because: (1) the maximum backdoor effectiveness is not reached at injection because of the dilution effect from normal local updates; (2) the backdoor effect decreases quickly as the backdoor will be overwritten by the newcoming normal local updates. In this paper, we strengthen the early-injected single-shot backdoor attack utilizing FL model information leakage. We show that the FL convergence can be expedited if the client trains on a dataset that mimics the distribution and gradients of the whole population. Based on this observation, we proposed a two-phase backdoor attack, which includes a preliminary phase for the subsequent backdoor attack. In the preliminary phase, the attacker-controlled client first launches a whole population distribution inference attack and then trains on a locally crafted dataset that is aligned with both the gradient and inferred distribution. Benefiting from the preliminary phase, the later injected backdoor achieves better effectiveness as the backdoor effect will be less likely to be diluted by the normal model updates. Extensive experiments are conducted on MNIST dataset under various data heterogeneity settings to evaluate the effectiveness of the proposed backdoor attack. Results show that the proposed backdoor outperforms existing backdoor attacks in both success rate and longevity, even when defense mechanisms are in place.