Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaygete at SemEval-2022 Task 4: RoBERTa based models for detecting Patronising and Condescending Language
Paper and Code
Apr 22, 2022
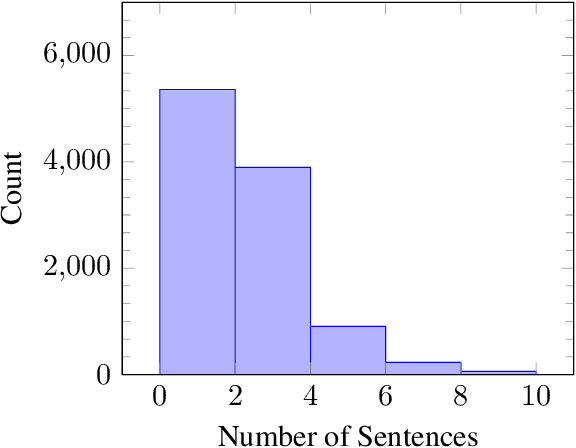
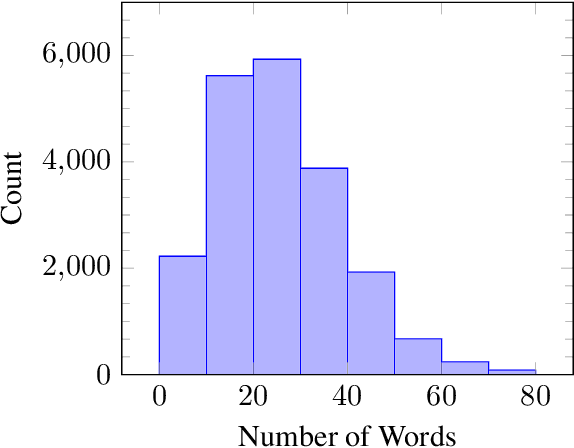
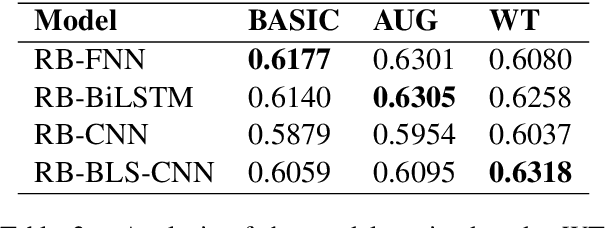
This work describes the development of different models to detect patronising and condescending language within extracts of news articles as part of the SemEval 2022 competition (Task-4). This work explores different models based on the pre-trained RoBERTa language model coupled with LSTM and CNN layers. The best models achieved 15$^{th}$ rank with an F1-score of 0.5924 for subtask-A and 12$^{th}$ in subtask-B with a macro-F1 score of 0.3763.
* Accepted at SemEval-2022, 7 pages, 6 Figures, 7 Tables
View paper on