 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Honeyword Generation with Language Models
Paper and Code
Aug 23, 2022
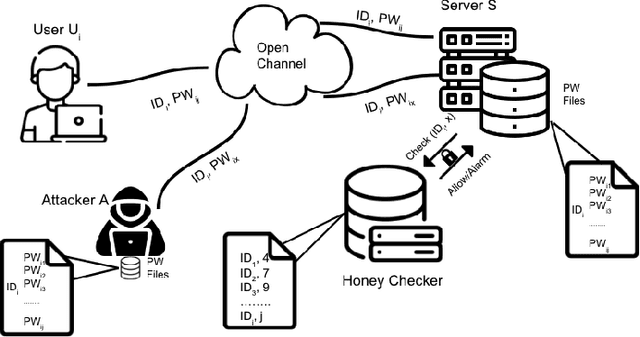


Honeywords are fictitious passwords inserted into databases in order to identify password breaches. The major difficulty is how to produce honeywords that are difficult to distinguish from real passwords. Although the generation of honeywords has been widely investigated in the past, the majority of existing research assumes attackers have no knowledge of the users. These honeyword generating techniques (HGTs) may utterly fail if attackers exploit users' personally identifiable information (PII) and the real passwords include users' PII. In this paper, we propose to build a more secure and trustworthy authentication system that employs off-the-shelf pre-trained language models which require no further training on real passwords to produce honeywords while retaining the PII of the associated real password, therefore significantly raising the bar for attackers. We conducted a pilot experiment in which individuals are asked to distinguish between authentic passwords and honeywords when the username is provided for GPT-3 and a tweaking technique. Results show that it is extremely difficult to distinguish the real passwords from the artifical ones for both techniques. We speculate that a larger sample size could reveal a significant difference between the two HGT techniques, favouring our proposed approach.