 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACRED Revisited: A Thorough Evaluation of the TACRED Relation Extraction Task
Paper and Code

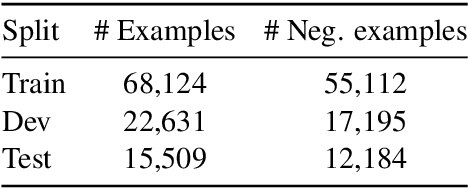
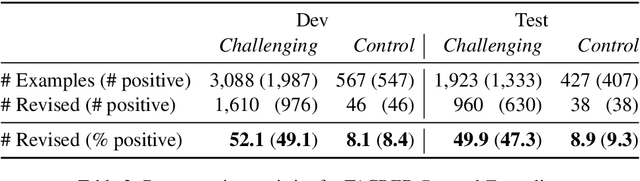
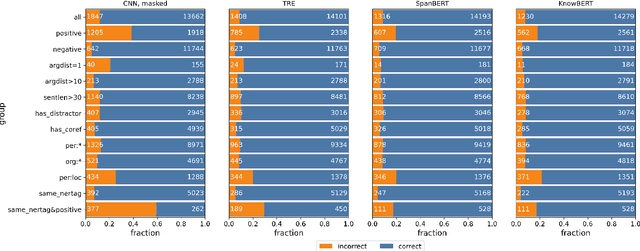
TACRED (Zhang et al., 2017) is one of the largest, most widely used crowdsourced datasets in Relation Extraction (RE). But, even with recent advances in unsupervised pre-training and knowledge enhanced neural RE, models still show a high error rate. In this paper, we investigate the questions: Have we reached a performance ceiling or is there still room for improvement? And how do crowd annotations, dataset, and models contribute to this error rate? To answer these questions, we first validate the most challenging 5K examples in the development and test sets using trained annotators. We find that label errors account for 8% absolute F1 test error, and that more than 50% of the examples need to be relabeled. On the relabeled test set the average F1 score of a large baseline model set improves from 62.1 to 70.1. After validation, we analyze misclassifications on the challenging instances, categorize them into linguistically motivated error groups, and verify the resulting error hypotheses on three state-of-the-art RE models. We show that two groups of ambiguous relations are responsible for most of the remaining errors and that models may adopt shallow heuristics on the dataset when entities are not masked.