 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematically improving existing k-means initialization algorithms at nearly no cost, by pairwise-nearest-neighbor smoothing
Paper and Code
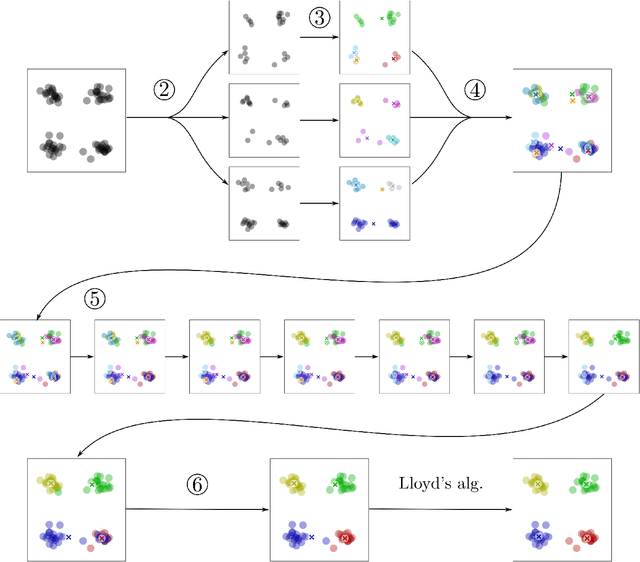
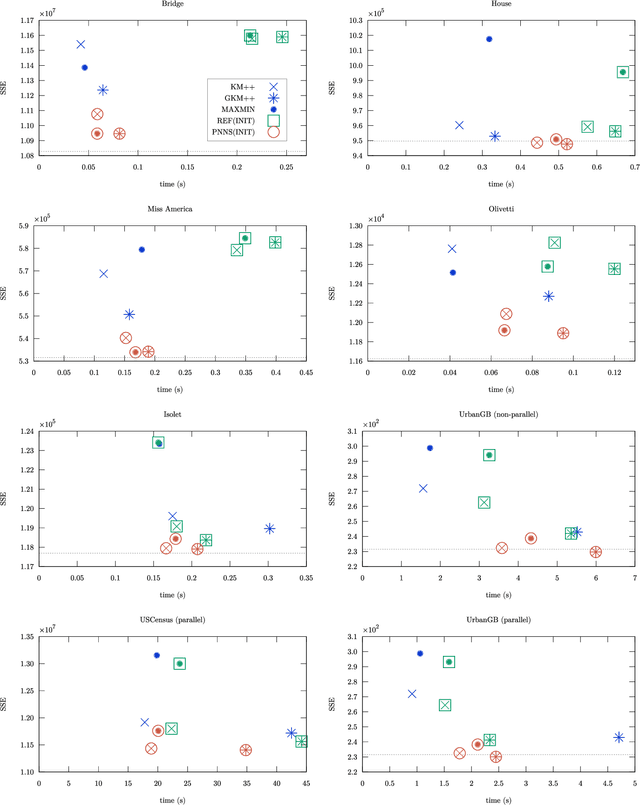
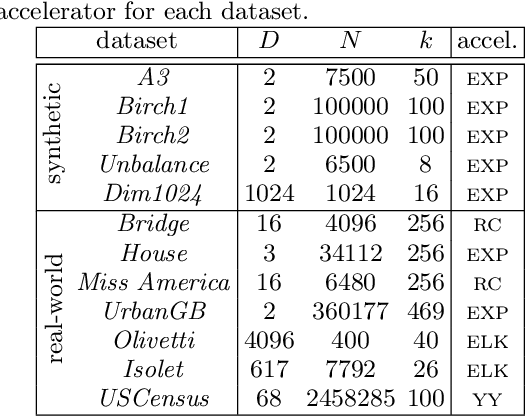
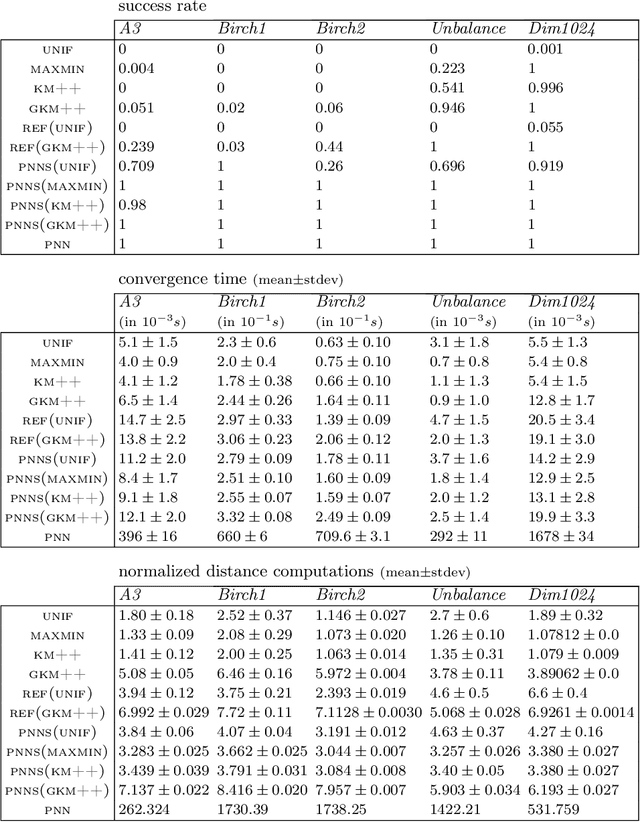
We present a meta-method for initializing (seeding) the $k$-means clustering algorithm called PNN-smoothing. It consists in splitting a given dataset into $J$ random subsets, clustering each of them individually, and merging the resulting clusterings with the pairwise-nearest-neighbor (PNN) method. It is a meta-method in the sense that when clustering the individual subsets any seeding algorithm can be used. If the computational complexity of that seeding algorithm is linear in the size of the data $N$ and the number of clusters $k$, PNN-smoothing is also almost linear with an appropriate choice of $J$, and in fact only at most a few percent slower in most cases in practice. We show empirically, using several existing seeding methods and testing on several synthetic and real datasets, that this procedure results in systematically better costs. It can even be applied recursively, and easily parallelized. Our implementation is publicly available at https://github.com/carlobaldassi/KMeansPNNSmoothing.jl