 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Test Data Generation Using Recurrent Neural Networks: A Position Paper
Paper and Code
Jul 07, 2024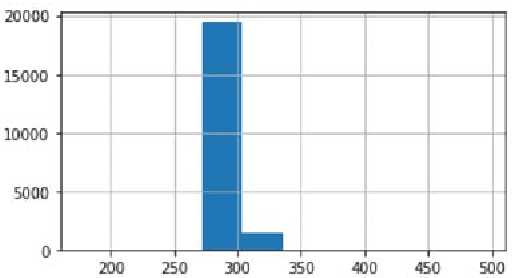
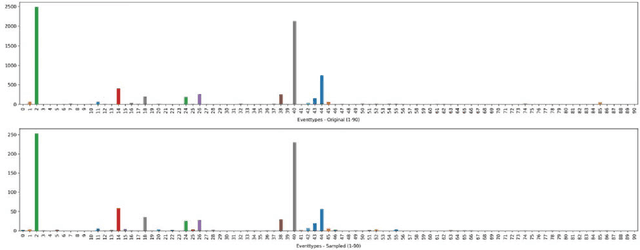

Testing in production-like test environments is an essential part of quality assurance processes in many industries. Provisioning of such test environments, for information-intensive services, involves setting up databases that are rich-enough to enable simulating a wide variety of user scenarios. While production data is perhaps the gold-standard here, many organizations, particularly within the public sectors, are not allowed to use production data for testing purposes due to privacy concerns. The alternatives are to use anonymized data, or synthetically generated data. In this paper, we elaborate on these alternatives and compare them in an industrial context. Further we focus on synthetic data generation and investigate the use of recurrent neural networks for this purpose. In our preliminary experiments, we were able to generate representative and highly accurate data using a recurrent neural network. These results open new research questions that we discuss here, and plan to investigate in our future research.