 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised learning Methods for Bangla Web Document Categorization
Paper and Code
Oct 08, 2014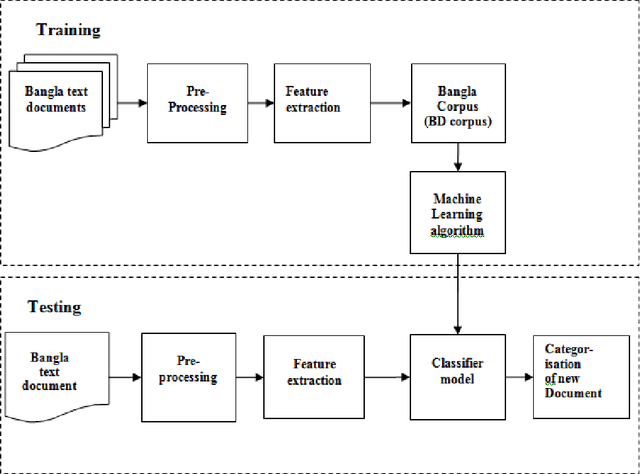
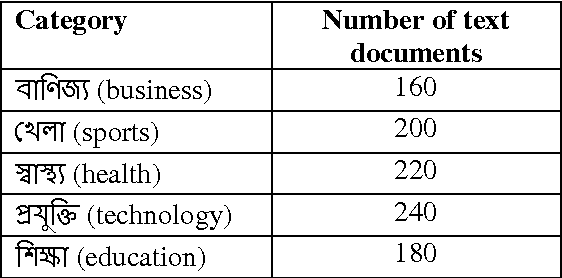
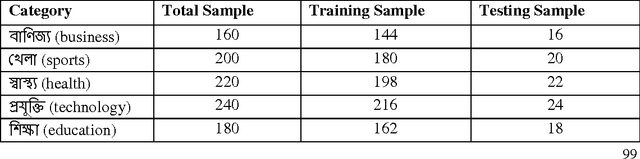
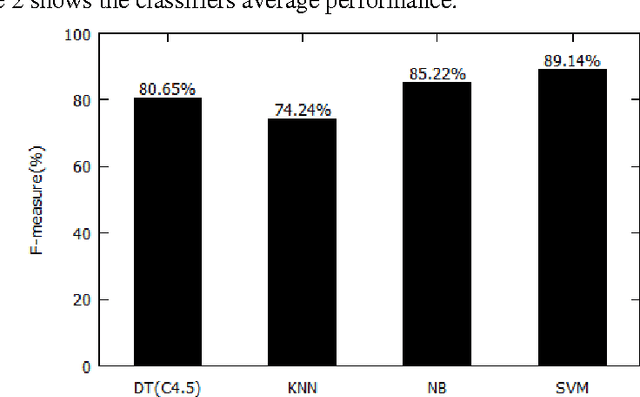
This paper explores the use of machine learning approaches, or more specifically, four supervised learning Methods, namely Decision Tree(C 4.5), K-Nearest Neighbour (KNN), Na\"ive Bays (NB), and Support Vector Machine (SVM) for categorization of Bangla web documents. This is a task of automatically sorting a set of documents into categories from a predefined set. Whereas a wide range of methods have been applied to English text categorization, relatively few studies have been conducted on Bangla language text categorization. Hence, we attempt to analyze the efficiency of those four methods for categorization of Bangla documents. In order to validate, Bangla corpus from various websites has been developed and used as examples for the experiment. For Bangla, empirical results support that all four methods produce satisfactory performance with SVM attaining good result in terms of high dimensional and relatively noisy document feature vectors.