 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy of the performance and scalability of federated learning for medical imaging with intermittent clients
Paper and Code
Jul 19, 2022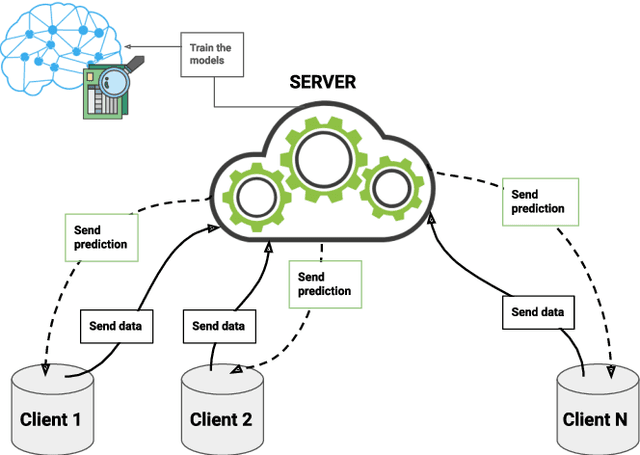
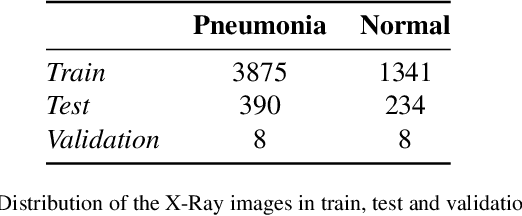
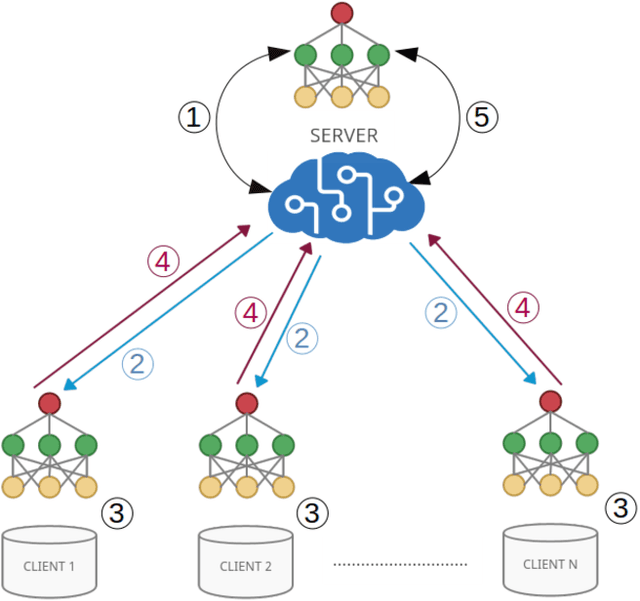
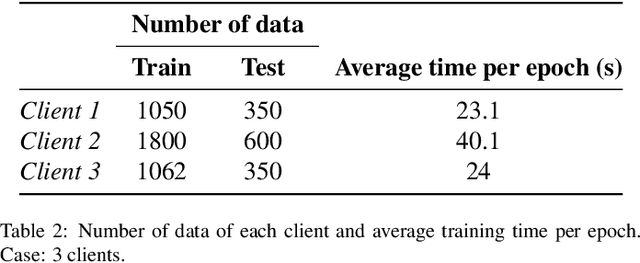
Federated learning is a data decentralization privacy-preserving technique used to perform machine or deep learning in a secure way. In this paper we present theoretical aspects about federated learning, such as the presentation of an aggregation operator, different types of federated learning, and issues to be taken into account in relation to the distribution of data from the clients, together with the exhaustive analysis of a use case where the number of clients varies. Specifically, a use case of medical image analysis is proposed, using chest X-ray images obtained from an open data repository. In addition to the advantages related to privacy, improvements in predictions (in terms of accuracy and area under the curve) and reduction of execution times will be studied with respect to the classical case (the centralized approach). Different clients will be simulated from the training data, selected in an unbalanced manner, i.e., they do not all have the same number of data. The results of considering three or ten clients are exposed and compared between them and against the centralized case. Two approaches to follow will be analyzed in the case of intermittent clients, as in a real scenario some clients may leave the training, and some new ones may enter the training. The evolution of the results for the test set in terms of accuracy, area under the curve and execution time is shown as the number of clients into which the original data is divided increases. Finally, improvements and future work in the field are proposed.