 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStay Positive: Knowledge Graph Embedding Without Negative Sampling
Paper and Code
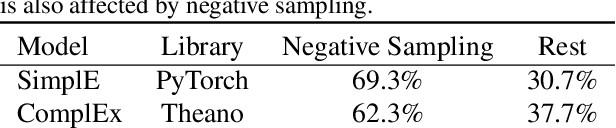
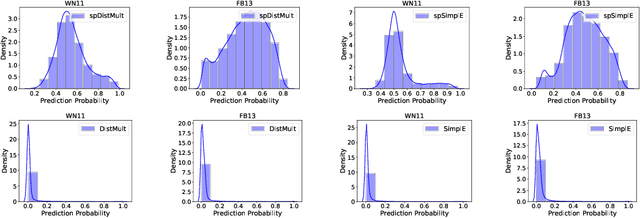
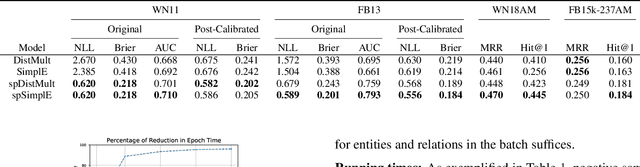
Knowledge graphs (KGs) are typically incomplete and we often wish to infer new facts given the existing ones. This can be thought of as a binary classification problem; we aim to predict if new facts are true or false. Unfortunately, we generally only have positive examples (the known facts) but we also need negative ones to train a classifier. To resolve this, it is usual to generate negative examples using a negative sampling strategy. However, this can produce false negatives which may reduce performance, is computationally expensive, and does not produce calibrated classification probabilities. In this paper, we propose a training procedure that obviates the need for negative sampling by adding a novel regularization term to the loss function. Our results for two relational embedding models (DistMult and SimplE) show the merit of our proposal both in terms of performance and speed.