 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStar Attention: Efficient LLM Inference over Long Sequences
Paper and Code



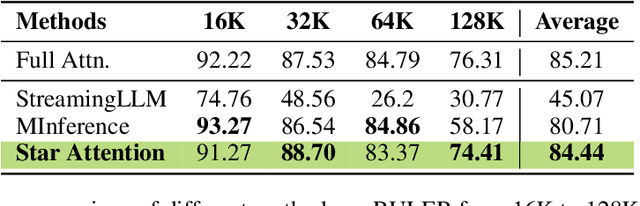
Inference with Transformer-based Large Language Models (LLMs) on long sequences is both costly and slow due to the quadratic complexity of the self-attention mechanism. We introduce Star Attention, a two-phase block-sparse approximation that improves computational efficiency by sharding attention across multiple hosts while minimizing communication overhead. In the first phase, the context is processed using blockwise-local attention across hosts, in parallel. In the second phase, query and response tokens attend to all prior cached tokens through sequence-global attention. Star Attention integrates seamlessly with most Transformer-based LLMs trained with global attention, reducing memory requirements and inference time by up to 11x while preserving 95-100% of accuracy.