 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable recovery of deep linear networks under sparsity constraints
Paper and Code
Feb 20, 2018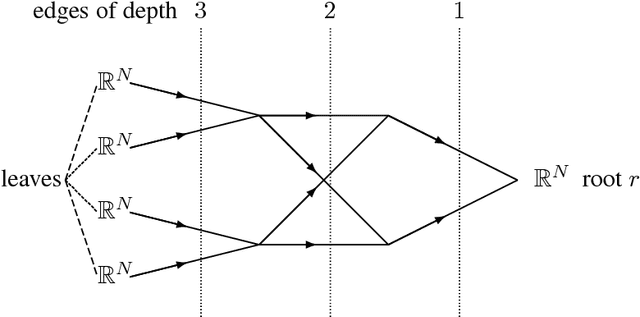
We study a deep linear network expressed under the form of a matrix factorization problem. It takes as input a matrix $X$ obtained by multiplying $K$ matrices (called factors and corresponding to the action of a layer). Each factor is obtained by applying a fixed linear operator to a vector of parameters satisfying a sparsity constraint. In machine learning, the error between the product of the estimated factors and $X$ (i.e. the reconstruction error) relates to the statistical risk. The stable recovery of the parameters defining the factors is required in order to interpret the factors and the intermediate layers of the network. In this paper, we provide sharp conditions on the network topology under which the error on the parameters defining the factors (i.e. the stability of the recovered parameters) scales linearly with the reconstruction error (i.e. the risk). Therefore, under these conditions on the network topology, any successful learning tasks leads to robust and therefore interpretable layers. The analysis is based on the recently proposed Tensorial Lifting. The particularity of this paper is to consider a sparse prior. As an illustration, we detail the analysis and provide sharp guarantees for the stable recovery of convolutional linear network under sparsity prior. As expected, the condition are rather strong.