 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezeAttention: 2D Management of KV-Cache in LLM Inference via Layer-wise Optimal Budget
Paper and Code
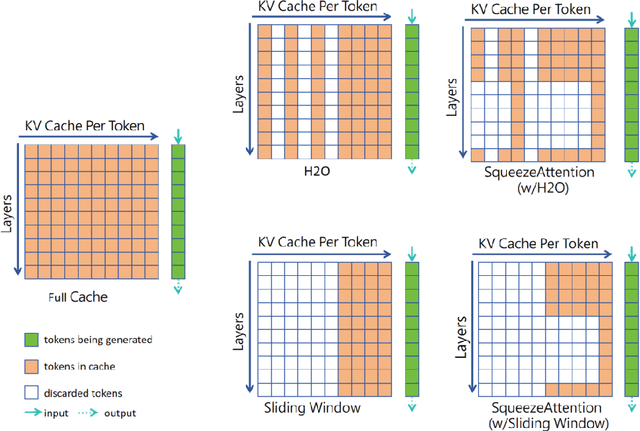
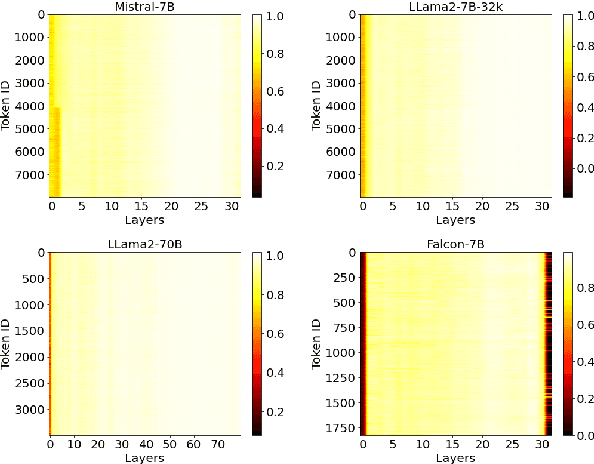

Optimizing the Key-Value (KV) cache of the Large Language Model (LLM) has been considered critical to saving the cost of inference. Most of the existing KV-cache compression algorithms attempted to sparsify the sequence of tokens by taking advantage of the different importance of tokens. In this work, we found that by identifying the importance of attention layers, we could optimize the KV-cache jointly from two dimensions. Based on our observations regarding layer-wise importance in inference, we propose SqueezeAttention to precisely optimize the allocation of KV-cache budget among layers on-the-fly and then incorporate three representative token sparsification algorithms to compress the KV-cache for each layer with its very own budget. By optimizing the KV-cache from both sequence's and layer's dimensions, SqueezeAttention achieves around 30% to 70% of the memory reductions and up to 2.2 times of throughput improvements in a wide range of LLMs and benchmarks. The code is available at https://github.com/hetailang/SqueezeAttention.