 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Optimization on Measures with Over-parameterized Gradient Descent
Paper and Code
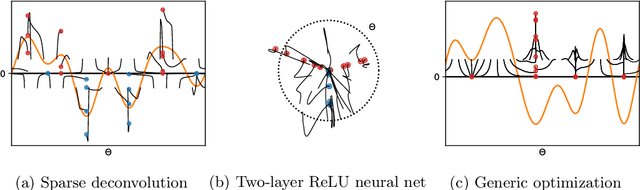
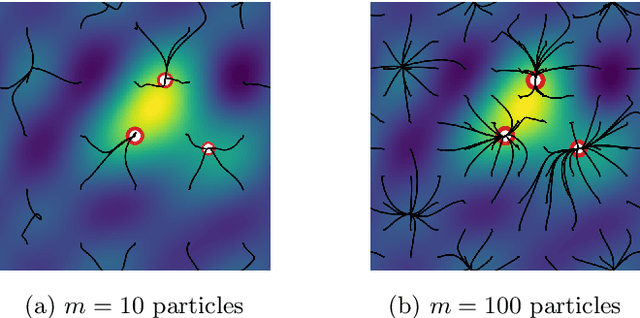
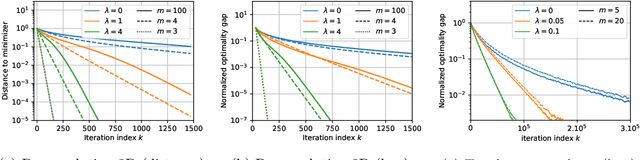
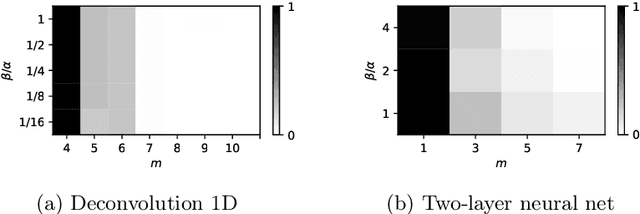
Minimizing a convex function of a measure with a sparsity-inducing penalty is a typical problem arising, e.g., in sparse spikes deconvolution or two-layer neural networks training. We show that this problem can be solved by discretizing the measure and running non-convex gradient descent on the positions and weights of the particles. For measures on a $d$-dimensional manifold and under some non-degeneracy assumptions, this leads to a global optimization algorithm with a complexity scaling as $\log(1/\epsilon)$ in the desired accuracy $\epsilon$, instead of $\epsilon^{-d}$ for convex methods. The key theoretical tools are a local convergence analysis in Wasserstein space and an analysis of a perturbed mirror descent in the space of measures. Our bounds involve quantities that are exponential in $d$ which is unavoidable under our assumptions.