 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Mixers: Combining MoE and Mixing to build a more efficient BERT
Paper and Code
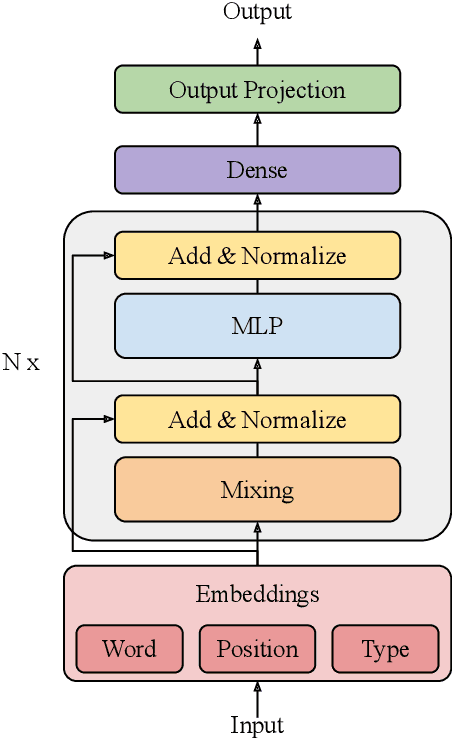
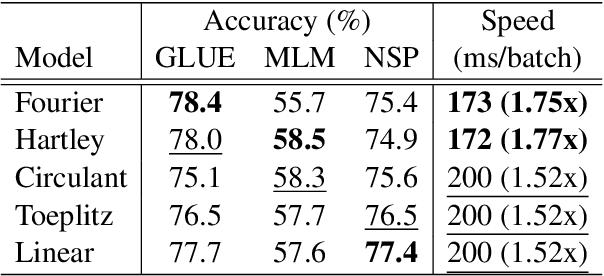
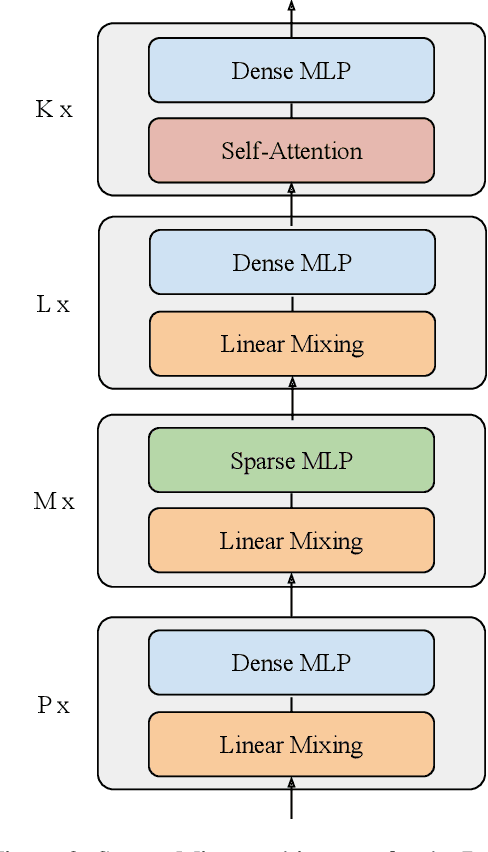
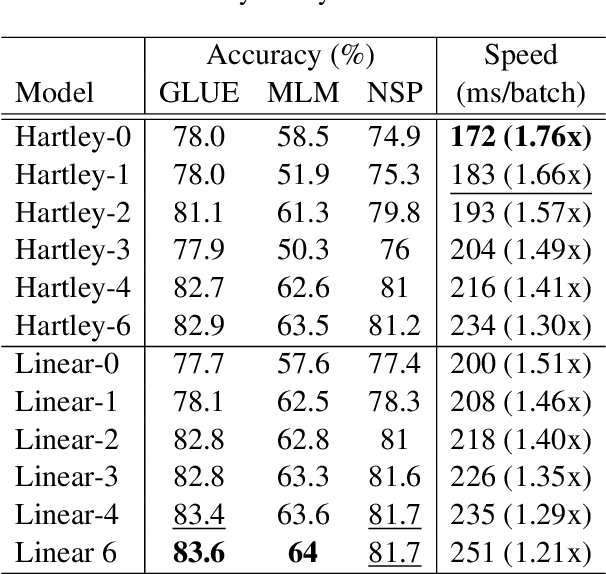
We combine the capacity of sparsely gated Mixture-of-Experts (MoE) with the speed and stability of linear, mixing transformations to design the Sparse Mixer encoder model. The Sparse Mixer slightly outperforms (<1%) BERT on GLUE and SuperGLUE, but more importantly trains 65% faster and runs inference 61% faster. We also present a faster variant, prosaically named Fast Sparse Mixer, that marginally underperforms (<0.2%) BERT on SuperGLUE, but trains and runs nearly twice as fast: 89% faster training and 98% faster inference. We justify the design of these two models by carefully ablating through various mixing mechanisms, MoE configurations and model hyperparameters. The Sparse Mixer overcomes many of the latency and stability concerns of MoE models and offers the prospect of serving sparse student models, without resorting to distilling them to dense variants.