 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse, Efficient, and Semantic Mixture Invariant Training: Taming In-the-Wild Unsupervised Sound Separation
Paper and Code
Jun 01, 2021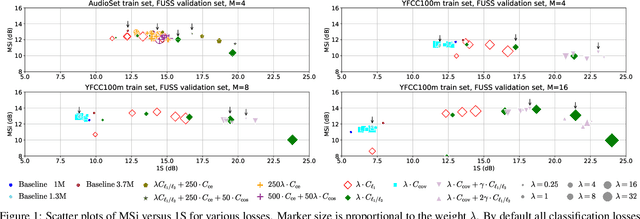
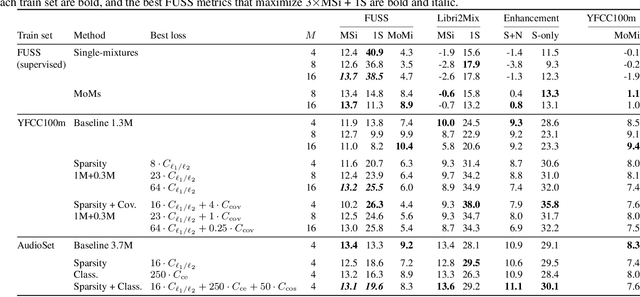
Supervised neural network training has led to significant progress on single-channel sound separation. This approach relies on ground truth isolated sources, which precludes scaling to widely available mixture data and limits progress on open-domain tasks. The recent mixture invariant training (MixIT) method enables training on in-the wild data; however, it suffers from two outstanding problems. First, it produces models which tend to over-separate, producing more output sources than are present in the input. Second, the exponential computational complexity of the MixIT loss limits the number of feasible output sources. These problems interact: increasing the number of output sources exacerbates over-separation. In this paper we address both issues. To combat over-separation we introduce new losses: sparsity losses that favor fewer output sources and a covariance loss that discourages correlated outputs. We also experiment with a semantic classification loss by predicting weak class labels for each mixture. To extend MixIT to larger numbers of sources, we introduce an efficient approximation using a fast least-squares solution, projected onto the MixIT constraint set. Our experiments show that the proposed losses curtail over-separation and improve overall performance. The best performance is achieved using larger numbers of output sources, enabled by our efficient MixIT loss, combined with sparsity losses to prevent over-separation. On the FUSS test set, we achieve over 13 dB in multi-source SI-SNR improvement, while boosting single-source reconstruction SI-SNR by over 17 dB.