 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanish and English Phoneme Recognition by Training on Simulated Classroom Audio Recordings of Collaborative Learning Environments
Paper and Code



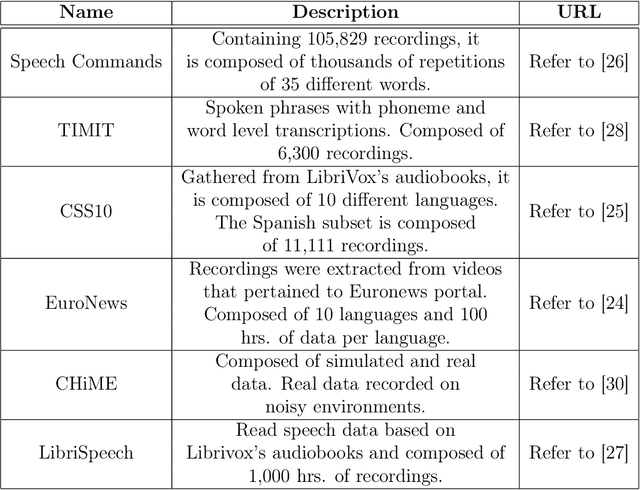
Audio recordings of collaborative learning environments contain a constant presence of cross-talk and background noise. Dynamic speech recognition between Spanish and English is required in these environments. To eliminate the standard requirement of large-scale ground truth, the thesis develops a simulated dataset by transforming audio transcriptions into phonemes and using 3D speaker geometry and data augmentation to generate an acoustic simulation of Spanish and English speech. The thesis develops a low-complexity neural network for recognizing Spanish and English phonemes (available at github.com/muelitas/keywordRec). When trained on 41 English phonemes, 0.099 PER is achieved on Speech Commands. When trained on 36 Spanish phonemes and tested on real recordings of collaborative learning environments, a 0.7208 LER is achieved. Slightly better than Google's Speech-to-text 0.7272 LER, which used anywhere from 15 to 1,635 times more parameters and trained on 300 to 27,500 hours of real data as opposed to 13 hours of simulated audios.