 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftmax Tempering for Training Neural Machine Translation Models
Paper and Code
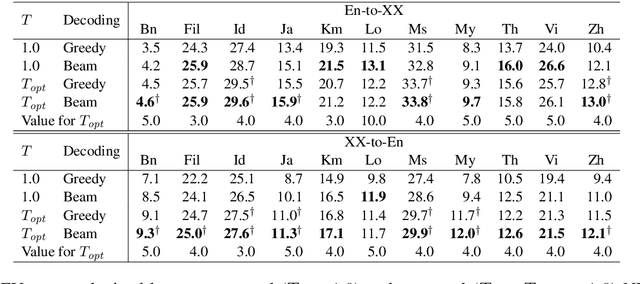
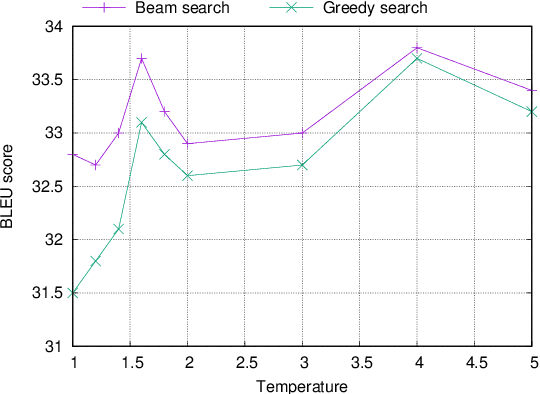
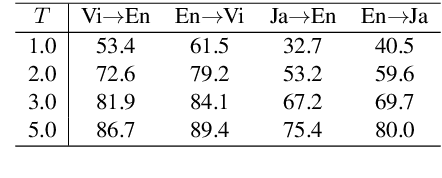
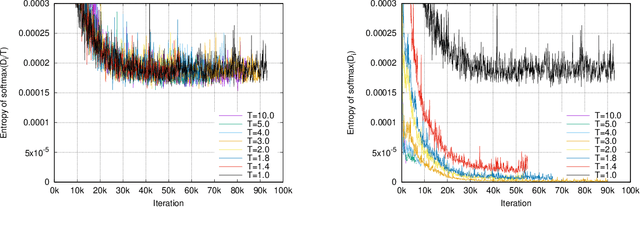
Neural machine translation (NMT) models are typically trained using a softmax cross-entropy loss where the softmax distribution is compared against smoothed gold labels. In low-resource scenarios, NMT models tend to over-fit because the softmax distribution quickly approaches the gold label distribution. To address this issue, we propose to divide the logits by a temperature coefficient, prior to applying softmax, during training. In our experiments on 11 language pairs in the Asian Language Treebank dataset and the WMT 2019 English-to-German translation task, we observed significant improvements in translation quality by up to 3.9 BLEU points. Furthermore, softmax tempering makes the greedy search to be as good as beam search decoding in terms of translation quality, enabling 1.5 to 3.5 times speed-up. We also study the impact of softmax tempering on multilingual NMT and recurrently stacked NMT, both of which aim to reduce the NMT model size by parameter sharing thereby verifying the utility of temperature in developing compact NMT models. Finally, an analysis of softmax entropies and gradients reveal the impact of our method on the internal behavior of NMT models.