 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOAK: Same/Other/All K-fold cross-validation for estimating similarity of patterns in data subsets
Paper and Code
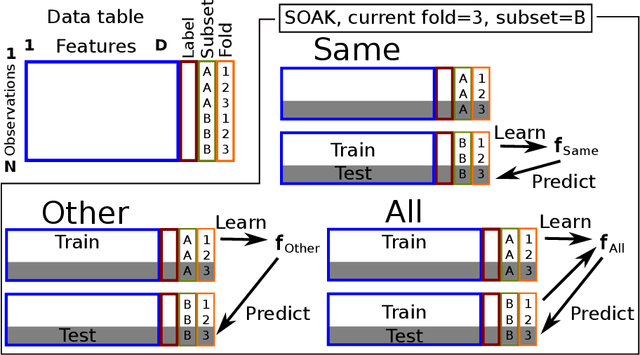
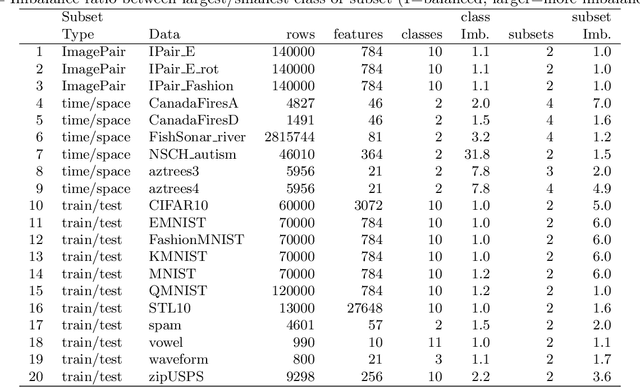

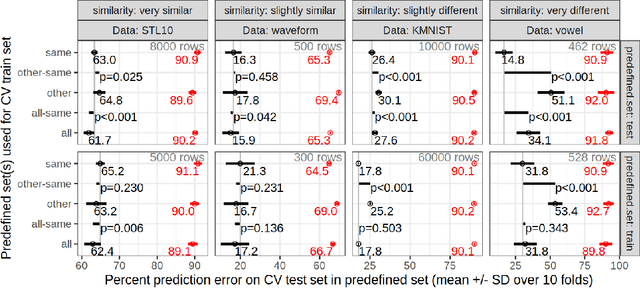
In many real-world applications of machine learning, we are interested to know if it is possible to train on the data that we have gathered so far, and obtain accurate predictions on a new test data subset that is qualitatively different in some respect (time period, geographic region, etc). Another question is whether data subsets are similar enough so that it is beneficial to combine subsets during model training. We propose SOAK, Same/Other/All K-fold cross-validation, a new method which can be used to answer both questions. SOAK systematically compares models which are trained on different subsets of data, and then used for prediction on a fixed test subset, to estimate the similarity of learnable/predictable patterns in data subsets. We show results of using SOAK on six new real data sets (with geographic/temporal subsets, to check if predictions are accurate on new subsets), 3 image pair data sets (subsets are different image types, to check that we get smaller prediction error on similar images), and 11 benchmark data sets with predefined train/test splits (to check similarity of predefined splits).