 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkel3D: Skeleton Guided Novel View Synthesis
Paper and Code
Dec 04, 2024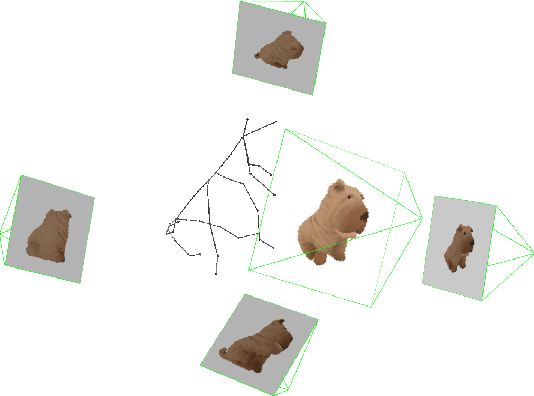

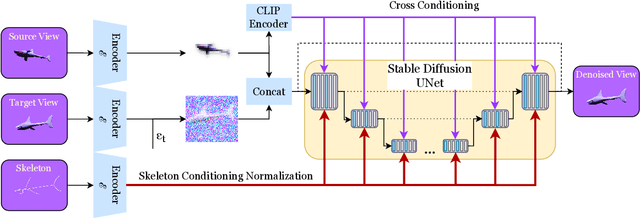
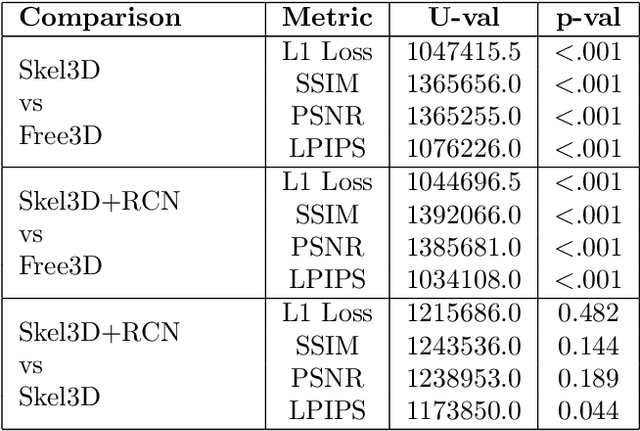
In this paper, we present an approach for monocular open-set novel view synthesis (NVS) that leverages object skeletons to guide the underlying diffusion model. Building upon a baseline that utilizes a pre-trained 2D image generator, our method takes advantage of the Objaverse dataset, which includes animated objects with bone structures. By introducing a skeleton guide layer following the existing ray conditioning normalization (RCN) layer, our approach enhances pose accuracy and multi-view consistency. The skeleton guide layer provides detailed structural information for the generative model, improving the quality of synthesized views. Experimental results demonstrate that our skeleton-guided method significantly enhances consistency and accuracy across diverse object categories within the Objaverse dataset. Our method outperforms existing state-of-the-art NVS techniques both quantitatively and qualitatively, without relying on explicit 3D representations.