 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Self Organizing Map with Visual Transformer
Paper and Code
Mar 06, 2025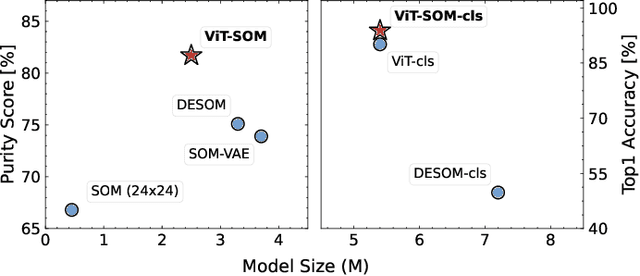
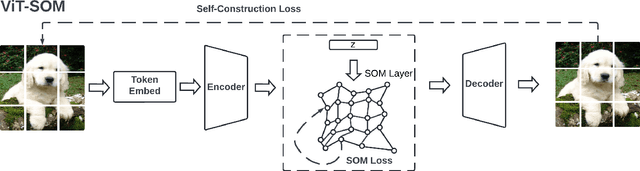
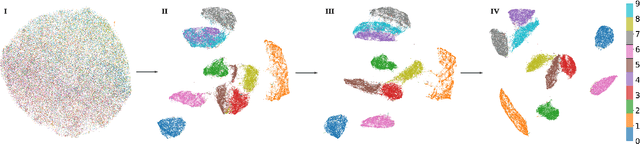
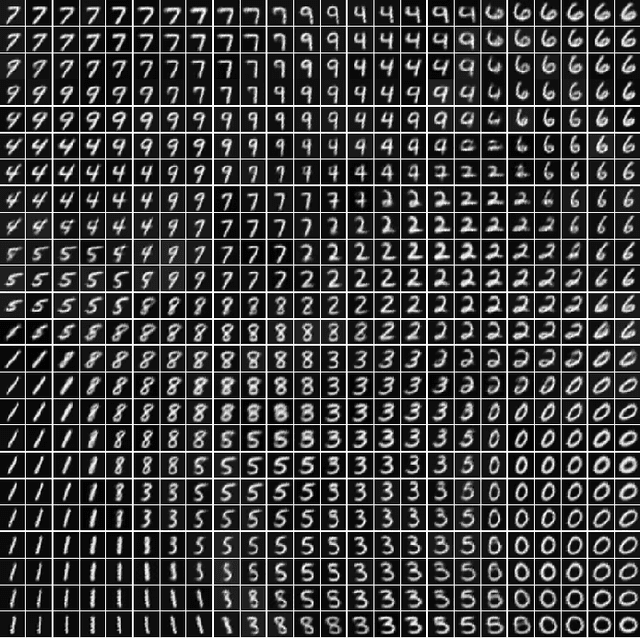
Vision Transformers (ViTs) have demonstrated exceptional performance in various vision tasks. However, they tend to underperform on smaller datasets due to their inherent lack of inductive biases. Current approaches address this limitation implicitly-often by pairing ViTs with pretext tasks or by distilling knowledge from convolutional neural networks (CNNs) to strengthen the prior. In contrast, Self-Organizing Maps (SOMs), a widely adopted self-supervised framework, are inherently structured to preserve topology and spatial organization, making them a promising candidate to directly address the limitations of ViTs in limited or small training datasets. Despite this potential, equipping SOMs with modern deep learning architectures remains largely unexplored. In this study, we conduct a novel exploration on how Vision Transformers (ViTs) and Self-Organizing Maps (SOMs) can empower each other, aiming to bridge this critical research gap. Our findings demonstrate that these architectures can synergistically enhance each other, leading to significantly improved performance in both unsupervised and supervised tasks. Code will be publicly available.