 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple, Scalable, and Stable Variational Deep Clustering
Paper and Code
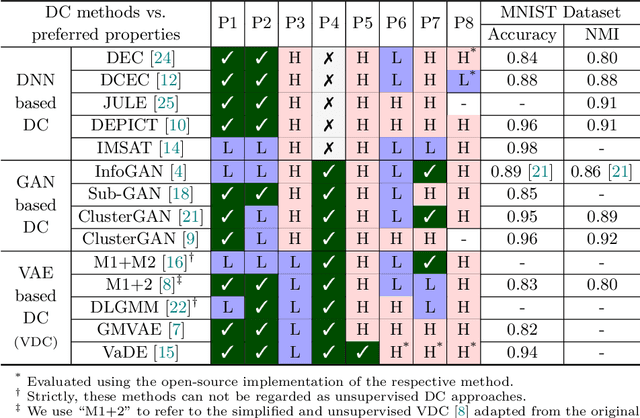
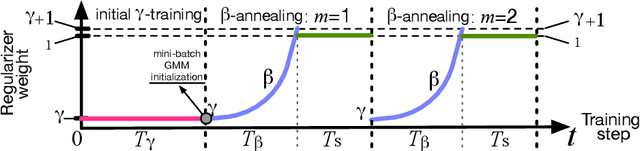
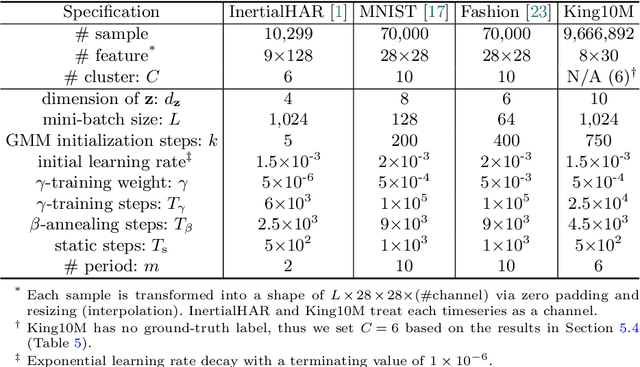

Deep clustering (DC) has become the state-of-the-art for unsupervised clustering. In principle, DC represents a variety of unsupervised methods that jointly learn the underlying clusters and the latent representation directly from unstructured datasets. However, DC methods are generally poorly applied due to high operational costs, low scalability, and unstable results. In this paper, we first evaluate several popular DC variants in the context of industrial applicability using eight empirical criteria. We then choose to focus on variational deep clustering (VDC) methods, since they mostly meet those criteria except for simplicity, scalability, and stability. To address these three unmet criteria, we introduce four generic algorithmic improvements: initial $\gamma$-training, periodic $\beta$-annealing, mini-batch GMM (Gaussian mixture model) initialization, and inverse min-max transform. We also propose a novel clustering algorithm S3VDC (simple, scalable, and stable VDC) that incorporates all those improvements. Our experiments show that S3VDC outperforms the state-of-the-art on both benchmark tasks and a large unstructured industrial dataset without any ground truth label. In addition, we analytically evaluate the usability and interpretability of S3VDC.