Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Text Topic Modeling: Application to tweets about Bitcoin
Paper and Code
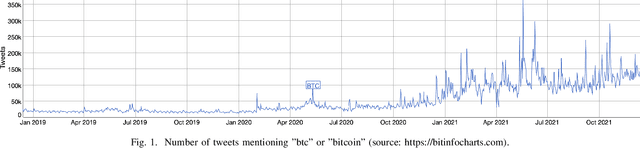

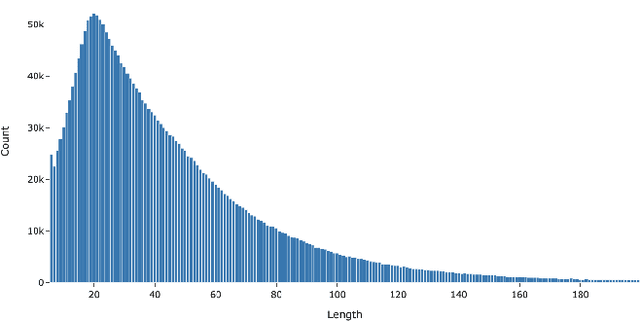

Understanding the semantic of a collection of texts is a challenging task. Topic models are probabilistic models that aims at extracting "topics" from a corpus of documents. This task is particularly difficult when the corpus is composed of short texts, such as posts on social networks. Following several previous research papers, we explore in this paper a set of collected tweets about bitcoin. In this work, we train three topic models and evaluate their output with several scores. We also propose a concrete application of the extracted topics.
View paper on