 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Aggregation and Rematerialization: Distributed Full-batch Training of Graph Neural Networks on Large Graphs
Paper and Code

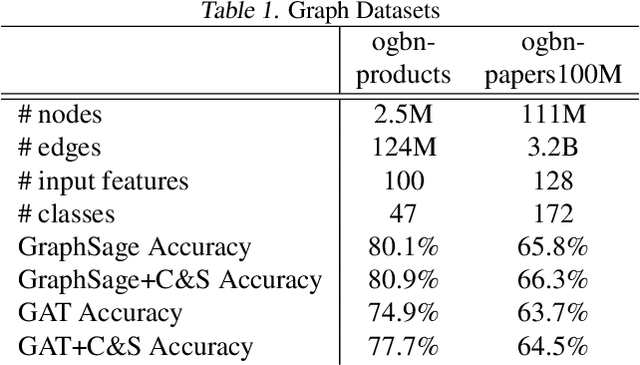


We present the Sequential Aggregation and Rematerialization (SAR) scheme for distributed full-batch training of Graph Neural Networks (GNNs) on large graphs. Large-scale training of GNNs has recently been dominated by sampling-based methods and methods based on non-learnable message passing. SAR on the other hand is a distributed technique that can train any GNN type directly on an entire large graph. The key innovation in SAR is the distributed sequential rematerialization scheme which sequentially re-constructs then frees pieces of the prohibitively large GNN computational graph during the backward pass. This results in excellent memory scaling behavior where the memory consumption per worker goes down linearly with the number of workers, even for densely connected graphs. Using SAR, we report the largest applications of full-batch GNN training to-date, and demonstrate large memory savings as the number of workers increases. We also present a general technique based on kernel fusion and attention-matrix rematerialization to optimize both the runtime and memory efficiency of attention-based models. We show that, coupled with SAR, our optimized attention kernels lead to significant speedups and memory savings in attention-based GNNs.