 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating the Effects of Batch Normalization on CNN Training Speed and Stability Using Classical Adaptive Filter Theory
Paper and Code
Feb 25, 2020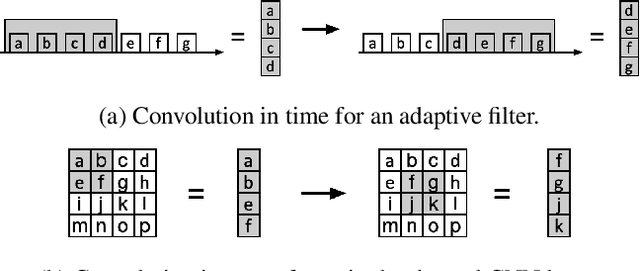
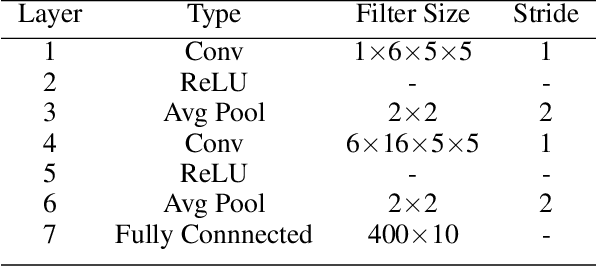
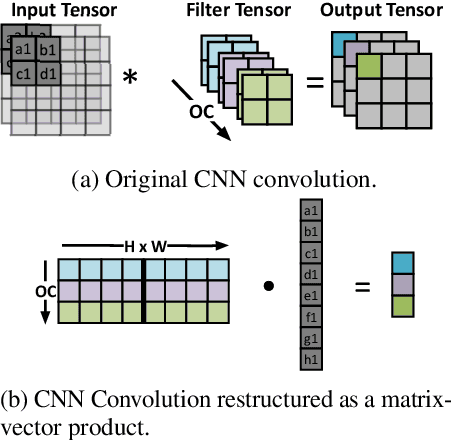
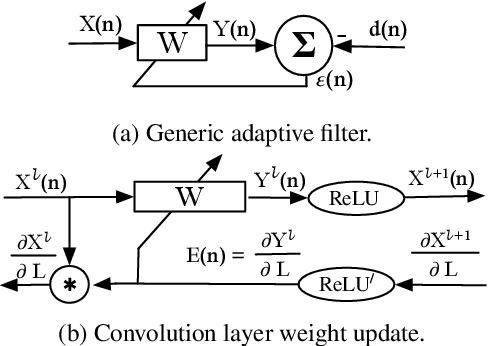
Batch Normalization (BatchNorm) is commonly used in Convolutional Neural Networks (CNNs) to improve training speed and stability. However, there is still limited consensus on why this technique is effective. This paper uses concepts from the traditional adaptive filter domain to provide insight into the dynamics and inner workings of BatchNorm. First, we show that the convolution weight updates have natural modes whose stability and convergence speed are tied to the eigenvalues of the input autocorrelation matrices, which are controlled by BatchNorm through the convolution layers' channel-wise structure. Furthermore, our experiments demonstrate that the speed and stability benefits are distinct effects. At low learning rates, it is BatchNorm's amplification of the smallest eigenvalues that improves convergence speed, while at high learning rates, it is BatchNorm's suppression of the largest eigenvalues that ensures stability. Lastly, we prove that in the first training step, when normalization is needed most, BatchNorm satisfies the same optimization as Normalized Least Mean Square (NLMS), while it continues to approximate this condition in subsequent steps. The analyses provided in this paper lay the groundwork for gaining further insight into the operation of modern neural network structures using adaptive filter theory.