 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-tuning hyper-parameters for unsupervised cross-lingual tokenization
Paper and Code
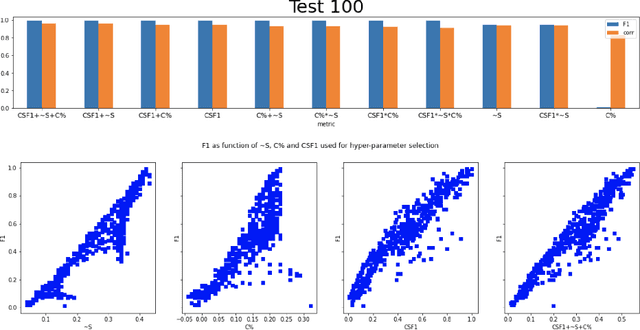

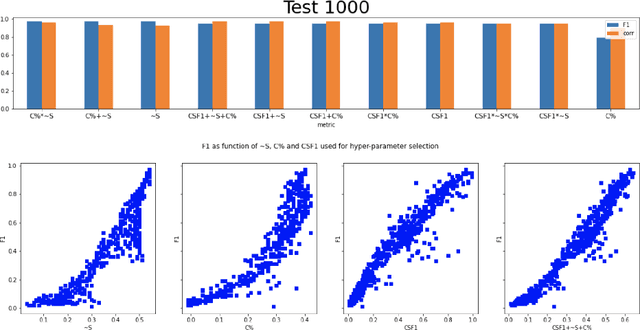

We explore the possibility of meta-learning for the language-independent unsupervised tokenization problem for English, Russian, and Chinese. We implement the meta-learning approach for automatic determination of hyper-parameters of the unsupervised tokenization model proposed in earlier works, relying on various human-independent fitness functions such as normalised anti-entropy, compression factor and cross-split F 1 score, as well as additive and multiplicative composite combinations of the three metrics, testing them against the conventional F1 tokenization score. We find a fairly good correlation between the latter and the additive combination of the former three metrics for English and Russian. In case of Chinese, we find a significant correlation between the F 1 score and the compression factor. Our results suggest the possibility of robust unsupervised tokenization of low-resource and dead languages and allow us to think about human languages in terms of the evolution of efficient symbolic communication codes with different structural optimisation schemes that have evolved in different human cultures.