Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning with Speech Modulation Dropout
Paper and Code
Mar 22, 2023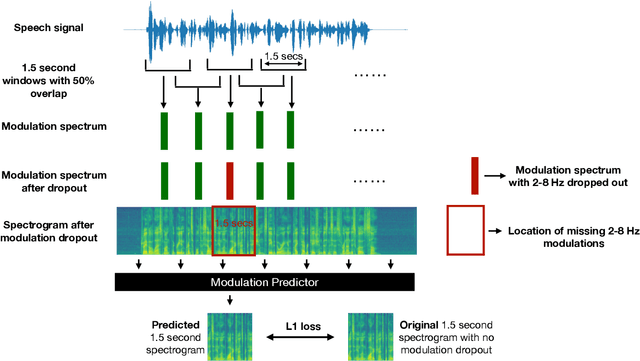

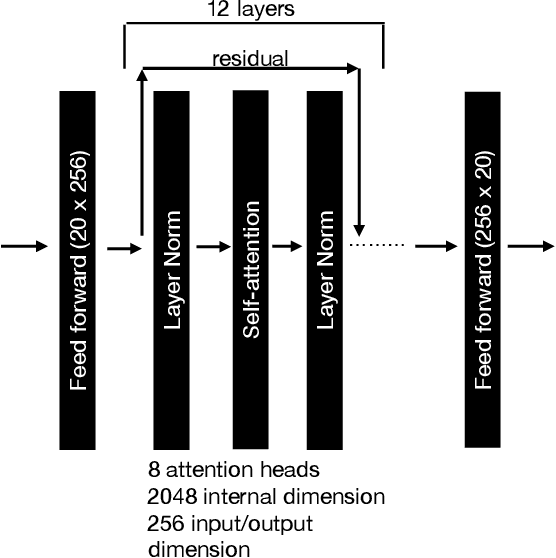
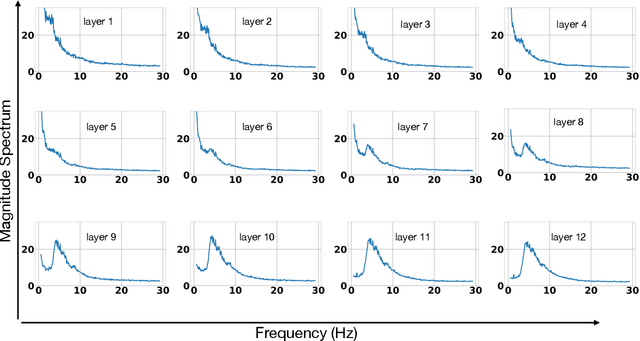
We show that training a multi-headed self-attention-based deep network to predict deleted, information-dense 2-8 Hz speech modulations over a 1.5-second section of a speech utterance is an effective way to make machines learn to extract speech modulations using time-domain contextual information. Our work exhibits that, once trained on large volumes of unlabelled data, the outputs of the self-attention layers vary in time with a modulation peak at 4 Hz. These pre-trained layers can be used to initialize parts of an Automatic Speech Recognition system to reduce its reliance on labeled speech data greatly.
View paper on