 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Using Just One Example
Paper and Code
Aug 14, 2024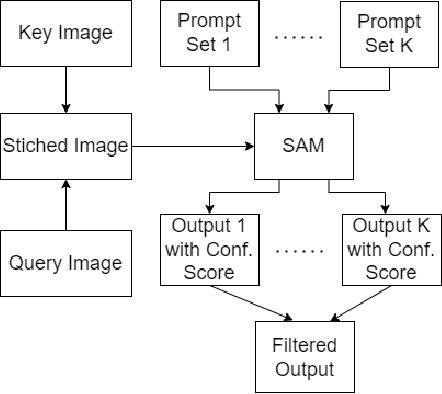
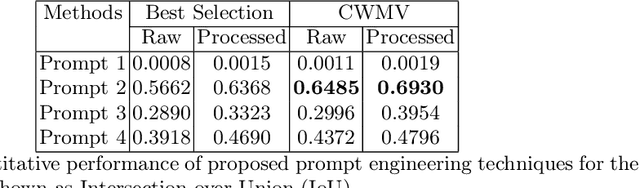
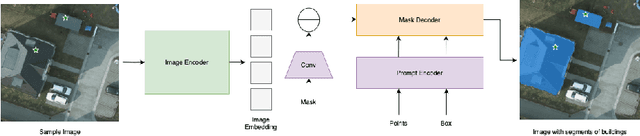

Semantic segmentation is an important topic in computer vision with many relevant application in Earth observation. While supervised methods exist, the constraints of limited annotated data has encouraged development of unsupervised approaches. However, existing unsupervised methods resemble clustering and cannot be directly mapped to explicit target classes. In this paper, we deal with single shot semantic segmentation, where one example for the target class is provided, which is used to segment the target class from query/test images. Our approach exploits recently popular Segment Anything (SAM), a promptable foundation model. We specifically design several techniques to automatically generate prompts from the only example/key image in such a way that the segmentation is successfully achieved on a stitch or concatenation of the example/key and query/test images. Proposed technique does not involve any training phase and just requires one example image to grasp the concept. Furthermore, no text-based prompt is required for the proposed method. We evaluated the proposed techniques on building and car classes.