 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for internal symbols underlying deep learning
Paper and Code
May 31, 2024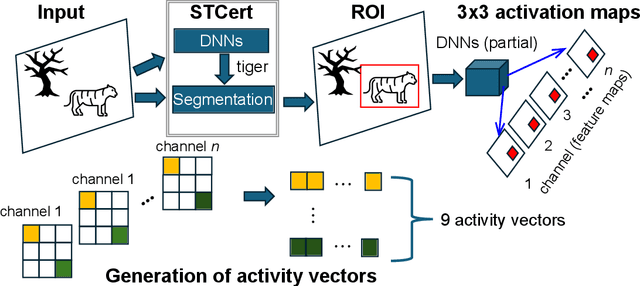

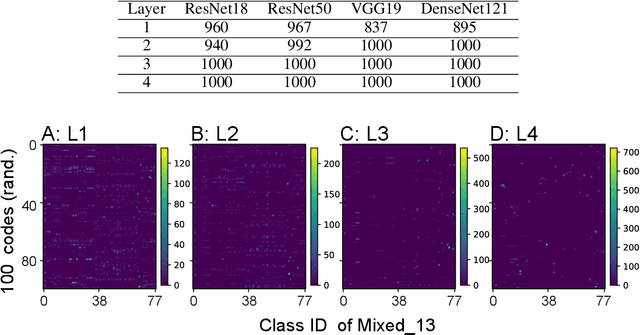
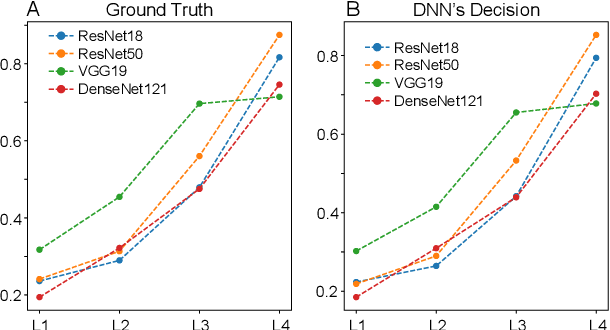
Deep learning (DL) enables deep neural networks (DNNs) to automatically learn complex tasks or rules from given examples without instructions or guiding principles. As we do not engineer DNNs' functions, it is extremely difficult to diagnose their decisions, and multiple lines of studies proposed to explain principles of DNNs/DL operations. Notably, one line of studies suggests that DNNs may learn concepts, the high level features recognizable to humans. Thus, we hypothesized that DNNs develop abstract codes, not necessarily recognizable to humans, which can be used to augment DNNs' decision-making. To address this hypothesis, we combined foundation segmentation models and unsupervised learning to extract internal codes and identify potential use of abstract codes to make DL's decision-making more reliable and safer.