 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Adversarial Attacks on Language Model Activations
Paper and Code
Dec 05, 2023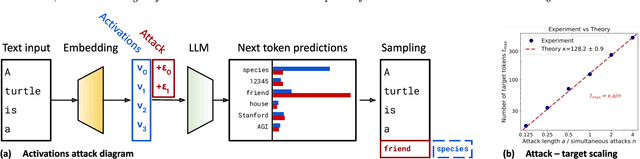
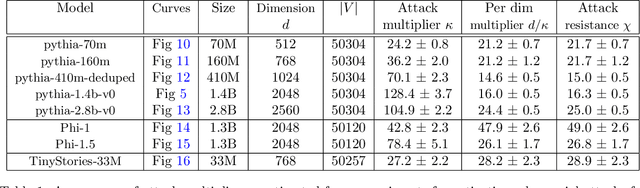

We explore a class of adversarial attacks targeting the activations of language models. By manipulating a relatively small subset of model activations, $a$, we demonstrate the ability to control the exact prediction of a significant number (in some cases up to 1000) of subsequent tokens $t$. We empirically verify a scaling law where the maximum number of target tokens $t_\mathrm{max}$ predicted depends linearly on the number of tokens $a$ whose activations the attacker controls as $t_\mathrm{max} = \kappa a$. We find that the number of bits of control in the input space needed to control a single bit in the output space (what we call attack resistance $\chi$) is remarkably constant between $\approx 16$ and $\approx 25$ over 2 orders of magnitude of model sizes for different language models. Compared to attacks on tokens, attacks on activations are predictably much stronger, however, we identify a surprising regularity where one bit of input steered either via activations or via tokens is able to exert control over a similar amount of output bits. This gives support for the hypothesis that adversarial attacks are a consequence of dimensionality mismatch between the input and output spaces. A practical implication of the ease of attacking language model activations instead of tokens is for multi-modal and selected retrieval models, where additional data sources are added as activations directly, sidestepping the tokenized input. This opens up a new, broad attack surface. By using language models as a controllable test-bed to study adversarial attacks, we were able to experiment with input-output dimensions that are inaccessible in computer vision, especially where the output dimension dominates.