 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and hyper-parameter-free non-parametric covariate shift adaptation with conditional sampling
Paper and Code
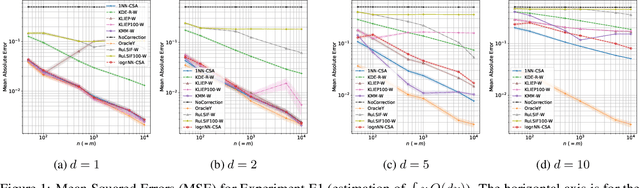
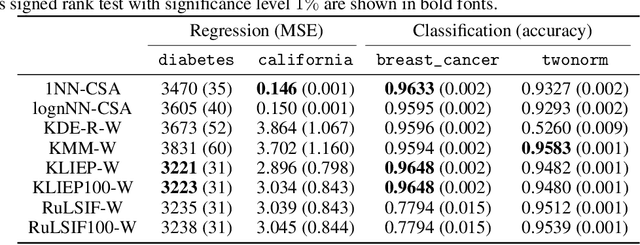
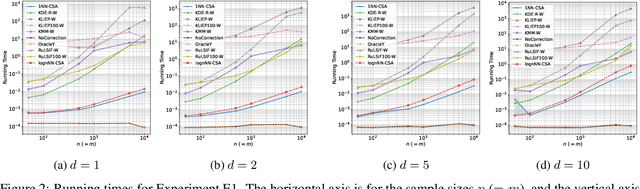
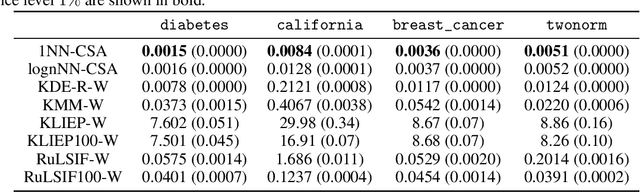
Many existing covariate shift adaptation methods estimate sample weights to be used in the risk estimation in order to mitigate the gap between the source and the target distribution. However, non-parametrically estimating the optimal weights typically involves computationally expensive hyper-parameter tuning that is crucial to the final performance. In this paper, we propose a new non-parametric approach to covariate shift adaptation which avoids estimating weights and has no hyper-parameter to be tuned. Our basic idea is to label unlabeled target data according to the $k$-nearest neighbors in the source dataset. Our analysis indicates that setting $k = 1$ is an optimal choice. Thanks to this property, there is no need to tune any hyper-parameters, unlike other non-parametric methods. Moreover, our method achieves a running time quasi-linear in the sample size with a theoretical guarantee, for the first time in the literature to the best of our knowledge. Our results include sharp rates of convergence for estimating the joint probability distribution of the target data. In particular, the variance of our estimators has the same rate of convergence as for standard parametric estimation despite their non-parametric nature. Our numerical experiments show that proposed method brings drastic reduction in the running time with accuracy comparable to that of the state-of-the-art methods.