 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVCHOI: Detecting Suspicious Activities using Dense Video Captioning with Human Object Interactions
Paper and Code
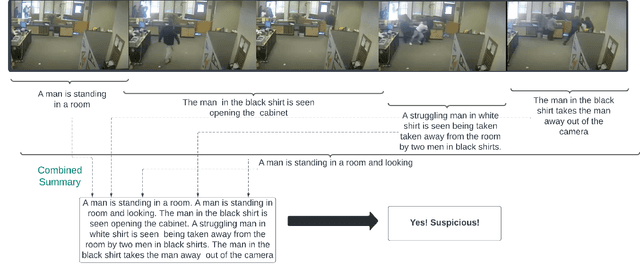
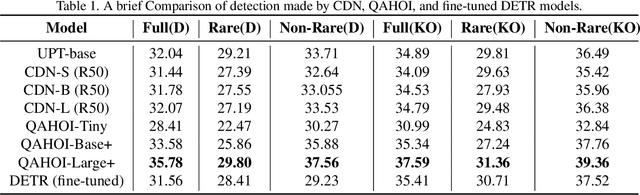


Detecting suspicious activities in surveillance videos has been a longstanding problem, which can further lead to difficulties in detecting crimes. The authors propose a novel approach for detecting and summarizing the suspicious activities going on in the surveillance videos. They also create ground truth summaries for the UCF-Crime video dataset. Further, the authors test existing state-of-the-art algorithms for Dense Video Captioning for a subset of this dataset and propose a model for this task by leveraging Human-Object Interaction models for the Visual features. They observe that this formulation for Dense Captioning achieves large gains over earlier approaches by a significant margin. The authors also perform an ablative analysis of the dataset and the model and report their findings.