 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Strategies for Static Powergrid Models
Paper and Code
Apr 19, 2022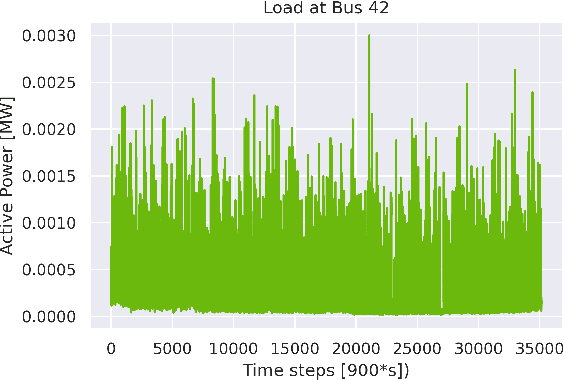
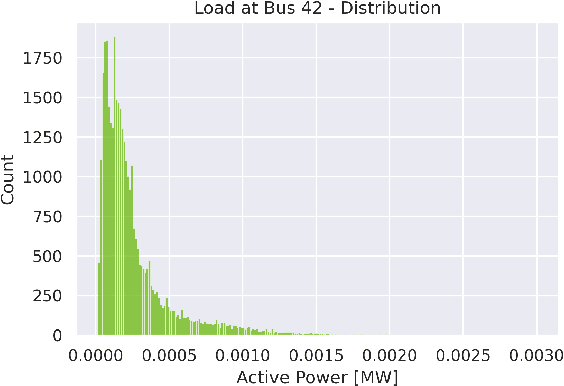
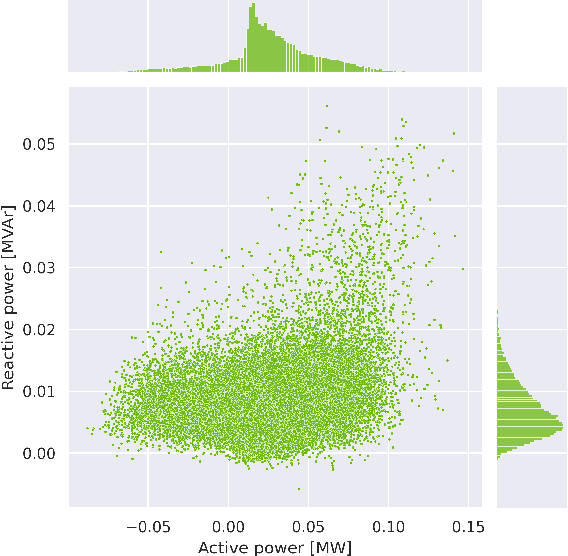
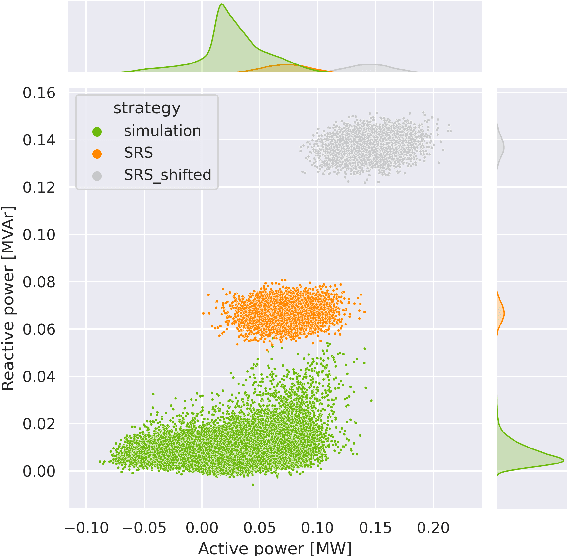
Machine learning and computational intelligence technologies gain more and more popularity as possible solution for issues related to the power grid. One of these issues, the power flow calculation, is an iterative method to compute the voltage magnitudes of the power grid's buses from power values. Machine learning and, especially, artificial neural networks were successfully used as surrogates for the power flow calculation. Artificial neural networks highly rely on the quality and size of the training data, but this aspect of the process is apparently often neglected in the works we found. However, since the availability of high quality historical data for power grids is limited, we propose the Correlation Sampling algorithm. We show that this approach is able to cover a larger area of the sampling space compared to different random sampling algorithms from the literature and a copula-based approach, while at the same time inter-dependencies of the inputs are taken into account, which, from the other algorithms, only the copula-based approach does.