 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Based Approaches to Handle Imbalances in Network Traffic Dataset for Machine Learning Techniques
Paper and Code
Nov 12, 2013
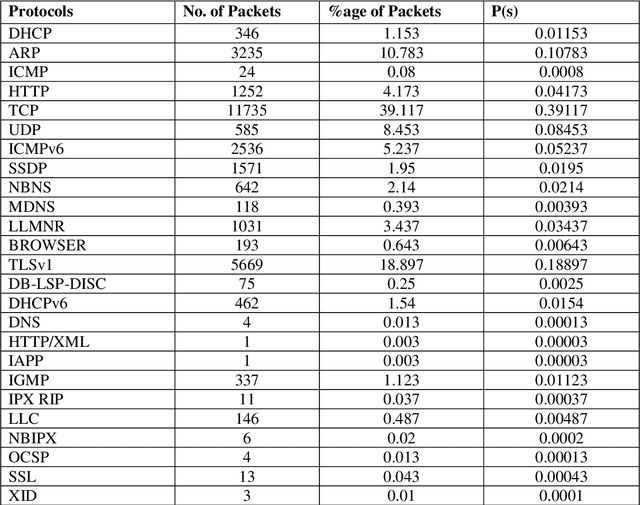
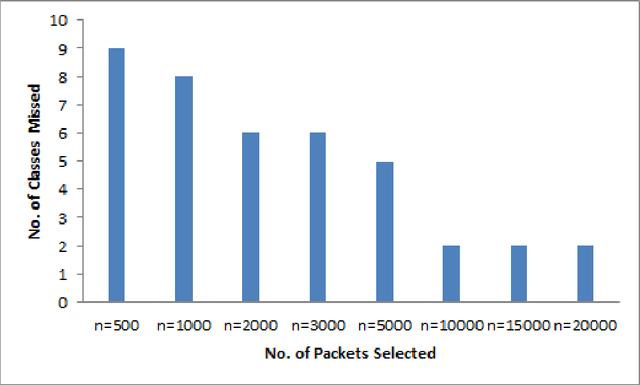
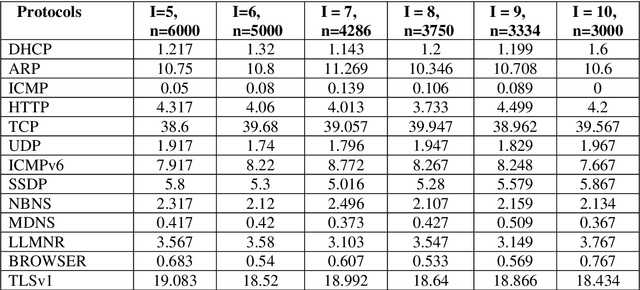
Network traffic data is huge, varying and imbalanced because various classes are not equally distributed. Machine learning (ML) algorithms for traffic analysis uses the samples from this data to recommend the actions to be taken by the network administrators as well as training. Due to imbalances in dataset, it is difficult to train machine learning algorithms for traffic analysis and these may give biased or false results leading to serious degradation in performance of these algorithms. Various techniques can be applied during sampling to minimize the effect of imbalanced instances. In this paper various sampling techniques have been analysed in order to compare the decrease in variation in imbalances of network traffic datasets sampled for these algorithms. Various parameters like missing classes in samples, probability of sampling of the different instances have been considered for comparison.