Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL agents Implicitly Learning Human Preferences
Paper and Code
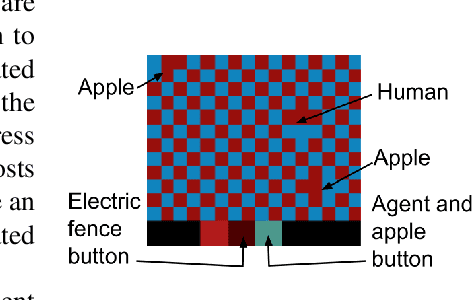
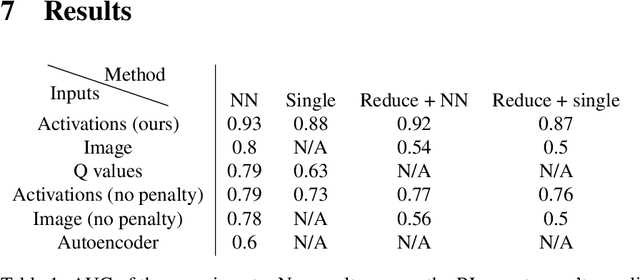
In the real world, RL agents should be rewarded for fulfilling human preferences. We show that RL agents implicitly learn the preferences of humans in their environment. Training a classifier to predict if a simulated human's preferences are fulfilled based on the activations of a RL agent's neural network gets .93 AUC. Training a classifier on the raw environment state gets only .8 AUC. Training the classifier off of the RL agent's activations also does much better than training off of activations from an autoencoder. The human preference classifier can be used as the reward function of an RL agent to make RL agent more beneficial for humans.
View paper on