 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Acoustic Features for Robust ASR
Paper and Code
Sep 24, 2024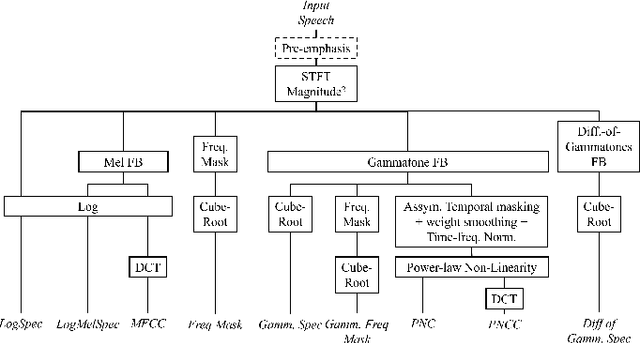
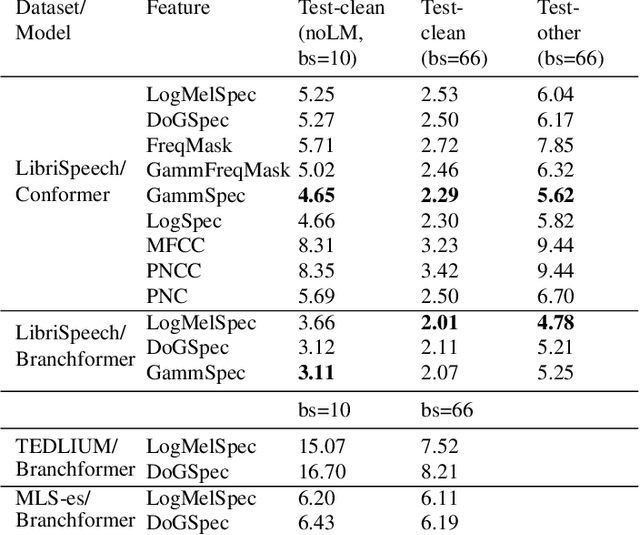
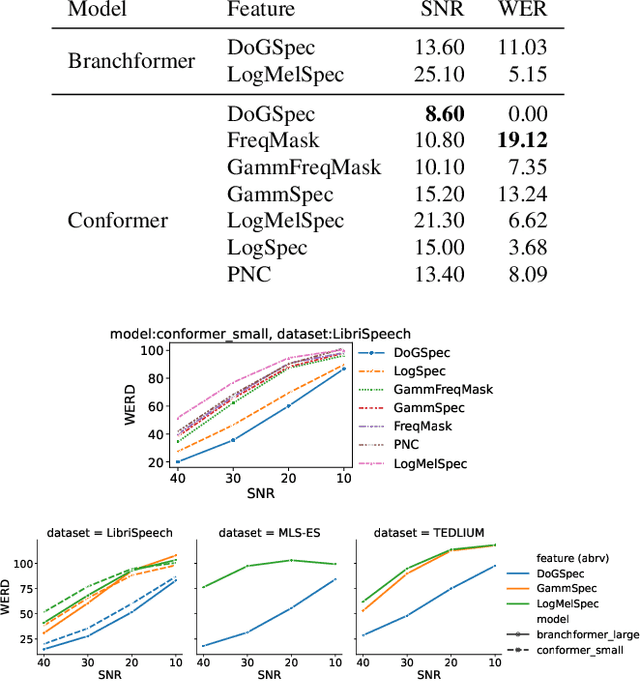
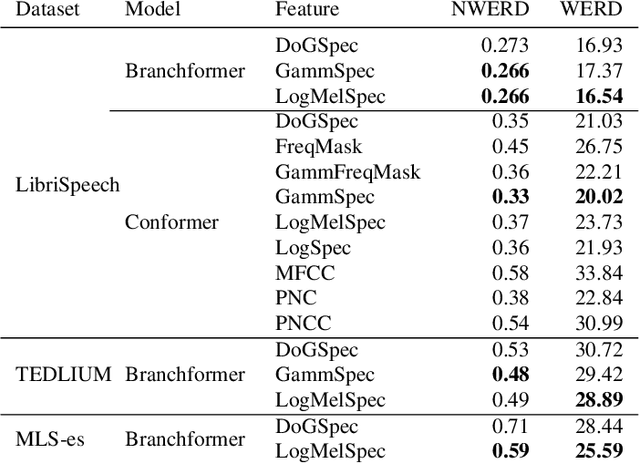
Automatic Speech Recognition (ASR) systems must be robust to the myriad types of noises present in real-world environments including environmental noise, room impulse response, special effects as well as attacks by malicious actors (adversarial attacks). Recent works seek to improve accuracy and robustness by developing novel Deep Neural Networks (DNNs) and curating diverse training datasets for them, while using relatively simple acoustic features. While this approach improves robustness to the types of noise present in the training data, it confers limited robustness against unseen noises and negligible robustness to adversarial attacks. In this paper, we revisit the approach of earlier works that developed acoustic features inspired by biological auditory perception that could be used to perform accurate and robust ASR. In contrast, Specifically, we evaluate the ASR accuracy and robustness of several biologically inspired acoustic features. In addition to several features from prior works, such as gammatone filterbank features (GammSpec), we also propose two new acoustic features called frequency masked spectrogram (FreqMask) and difference of gammatones spectrogram (DoGSpec) to simulate the neuro-psychological phenomena of frequency masking and lateral suppression. Experiments on diverse models and datasets show that (1) DoGSpec achieves significantly better robustness than the highly popular log mel spectrogram (LogMelSpec) with minimal accuracy degradation, and (2) GammSpec achieves better accuracy and robustness to non-adversarial noises from the Speech Robust Bench benchmark, but it is outperformed by DoGSpec against adversarial attacks.