 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of Methods for Handling Class-Imbalanced in Classification Problems
Paper and Code
Nov 10, 2022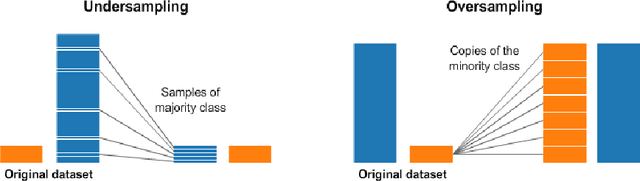
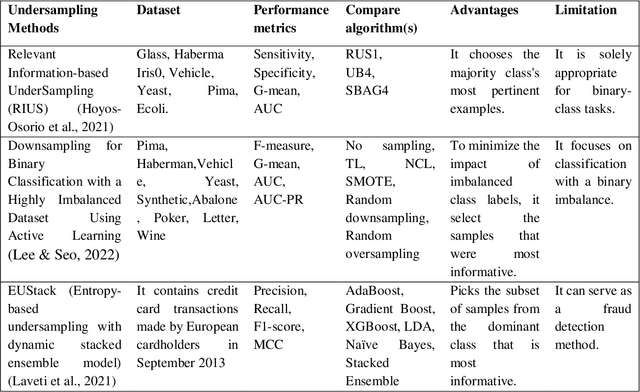
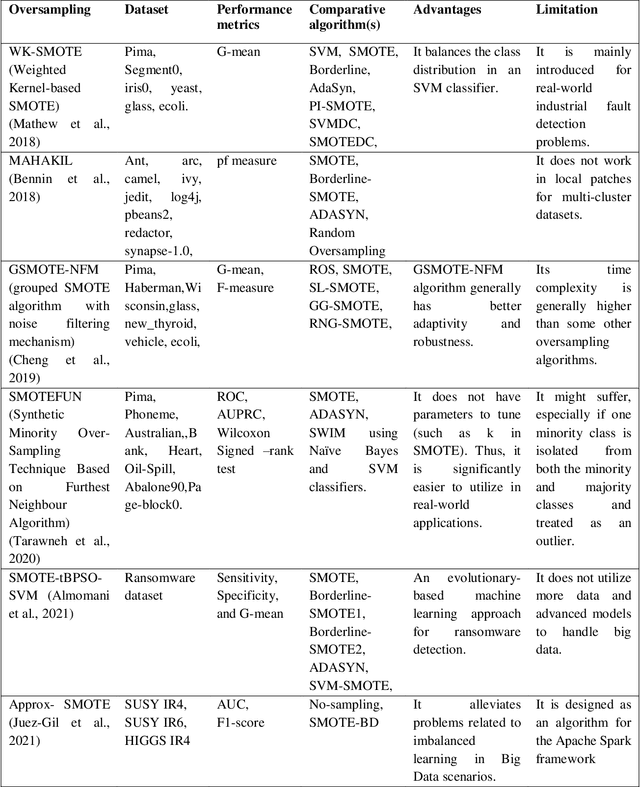
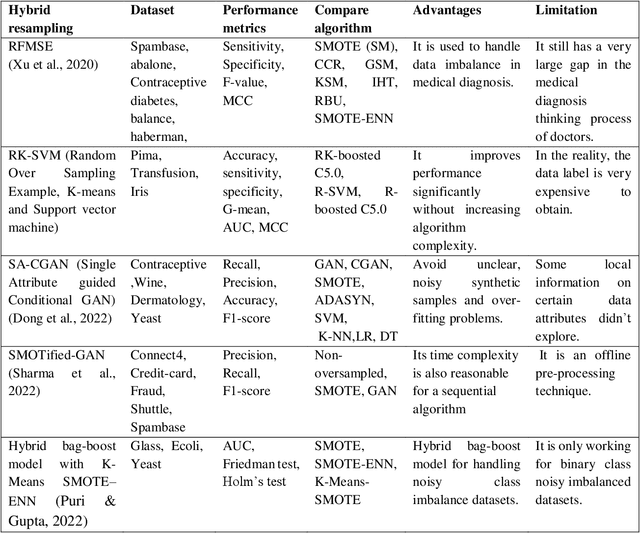
Learning classifiers using skewed or imbalanced datasets can occasionally lead to classification issues; this is a serious issue. In some cases, one class contains the majority of examples while the other, which is frequently the more important class, is nevertheless represented by a smaller proportion of examples. Using this kind of data could make many carefully designed machine-learning systems ineffective. High training fidelity was a term used to describe biases vs. all other instances of the class. The best approach to all possible remedies to this issue is typically to gain from the minority class. The article examines the most widely used methods for addressing the problem of learning with a class imbalance, including data-level, algorithm-level, hybrid, cost-sensitive learning, and deep learning, etc. including their advantages and limitations. The efficiency and performance of the classifier are assessed using a myriad of evaluation metrics.