 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of data types and model dimensionality for cardiac DTI SMS-related artefact removal
Paper and Code

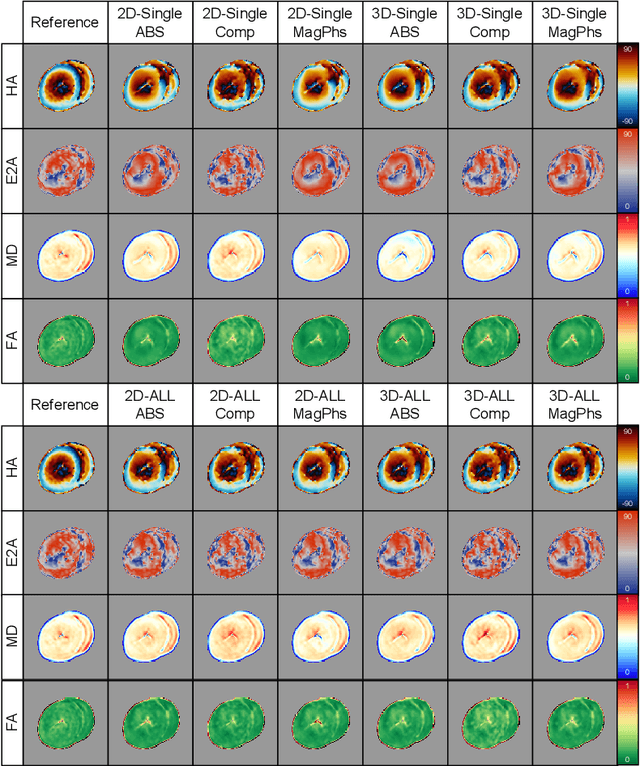
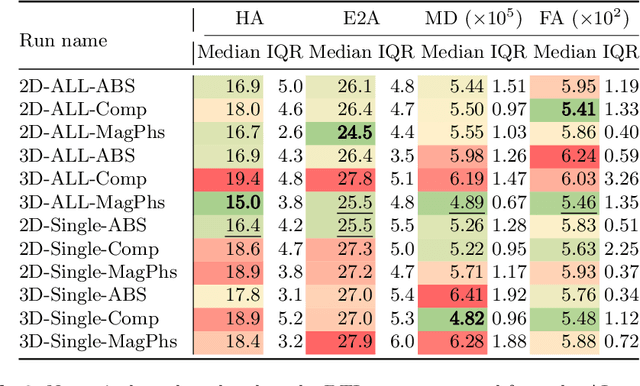
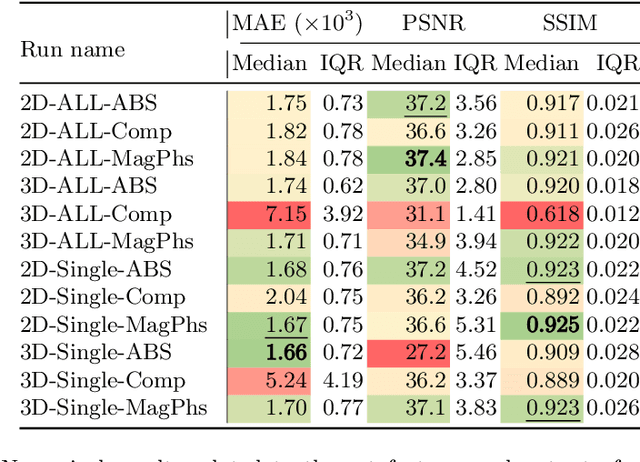
As diffusion tensor imaging (DTI) gains popularity in cardiac imaging due to its unique ability to non-invasively assess the cardiac microstructure, deep learning-based Artificial Intelligence is becoming a crucial tool in mitigating some of its drawbacks, such as the long scan times. As it often happens in fast-paced research environments, a lot of emphasis has been put on showing the capability of deep learning while often not enough time has been spent investigating what input and architectural properties would benefit cardiac DTI acceleration the most. In this work, we compare the effect of several input types (magnitude images vs complex images), multiple dimensionalities (2D vs 3D operations), and multiple input types (single slice vs multi-slice) on the performance of a model trained to remove artefacts caused by a simultaneous multi-slice (SMS) acquisition. Despite our initial intuition, our experiments show that, for a fixed number of parameters, simpler 2D real-valued models outperform their more advanced 3D or complex counterparts. The best performance is although obtained by a real-valued model trained using both the magnitude and phase components of the acquired data. We believe this behaviour to be due to real-valued models making better use of the lower number of parameters, and to 3D models not being able to exploit the spatial information because of the low SMS acceleration factor used in our experiments.