 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-guided Counterfactual Generation for QA
Paper and Code
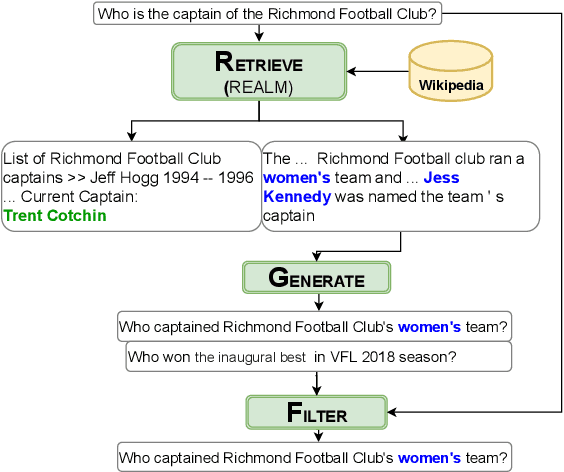


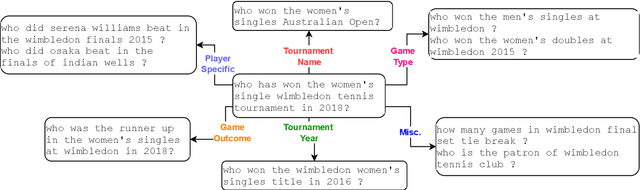
Deep NLP models have been shown to learn spurious correlations, leaving them brittle to input perturbations. Recent work has shown that counterfactual or contrastive data -- i.e. minimally perturbed inputs -- can reveal these weaknesses, and that data augmentation using counterfactuals can help ameliorate them. Proposed techniques for generating counterfactuals rely on human annotations, perturbations based on simple heuristics, and meaning representation frameworks. We focus on the task of creating counterfactuals for question answering, which presents unique challenges related to world knowledge, semantic diversity, and answerability. To address these challenges, we develop a Retrieve-Generate-Filter(RGF) technique to create counterfactual evaluation and training data with minimal human supervision. Using an open-domain QA framework and question generation model trained on original task data, we create counterfactuals that are fluent, semantically diverse, and automatically labeled. Data augmentation with RGF counterfactuals improves performance on out-of-domain and challenging evaluation sets over and above existing methods, in both the reading comprehension and open-domain QA settings. Moreover, we find that RGF data leads to significant improvements in a model's robustness to local perturbations.