Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults Merging in the Patent Domain
Paper and Code
Mar 01, 2022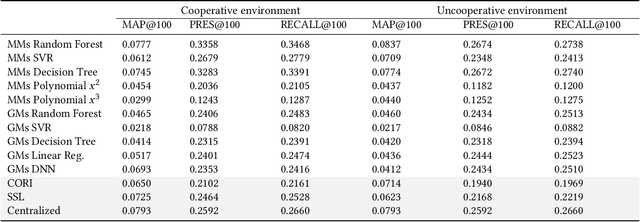
In this paper, we test machine learning methods for results merging in patent document retrieval. Specifically, we examine random forest, decision tree, support vector machine (SVR), linear regression, polynomial regression, and deep neural networks (DNNs). We use two different methods for results merging, the multiple models (MM) method and the global model method (GM). Furthermore, we examine whether the ranking of the document's scores is linearly explainable. The CLEF-IP 2011 standard test collection was used in our experiments. The random forest produces the best results in comparison to all other models, and it fits the data better than linear and polynomial approaches.
* ICPS Series ; PCI-2020: 24th Pan-Hellenic Conference on
Informatics ; Pages 229-232 * 5 pages
View paper on