 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Disentaglement via Regularization by Identification
Paper and Code
Feb 28, 2023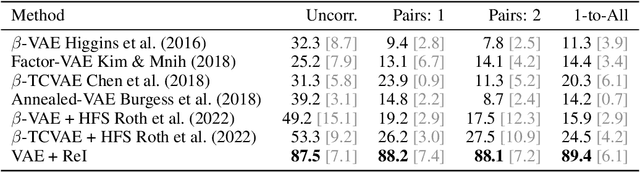



This work focuses on the problem of learning disentangled representations from observational data. Given observations ${\mathbf{x}^{(i)}}$ for $i=1,...,N $ drawn from $p(\mathbf{x}|\mathbf{y})$ with generative variables $\mathbf{y}$ admitting the distribution factorization $p(\mathbf{y}) = \prod_{c} p(\mathbf{y}_c )$ we ask whether learning disentangled representations matching the space of observations with identification guarantees on the posterior $p(\mathbf{z}| \mathbf{x}, \hat{\mathbf{y}}_c)$ for each $c$, is plausible. We argue modern deep representation learning models are ill-posed with collider bias behaviour; a source of bias producing entanglement between generating variables. Under the rubric of causality, we show this issue can be explained and reconciled under the condition of identifiability; attainable under supervision or a weak-form of it. For this, we propose regularization by identification (ReI), a regularization framework defined by the identification of the causal queries involved in the learning problem. Empirical evidence shows that enforcing ReI in a variational framework results in disentangled representations equipped with generalization capabilities to out-of-distribution examples and that aligns nicely with the true expected effect between generating variables and measurement apparatus.