Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance in Dialogue: Is Less More? An Empirical Comparison of Existing Metrics, and a Novel Simple Metric
Paper and Code
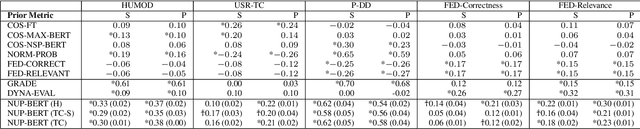

In this work, we evaluate various existing dialogue relevance metrics, find strong dependency on the dataset, often with poor correlation with human scores of relevance, and propose modifications to reduce data requirements and domain sensitivity while improving correlation. Our proposed metric achieves state-of-the-art performance on the HUMOD dataset while reducing measured sensitivity to dataset by 37%-66%. We achieve this without fine-tuning a pretrained language model, and using only 3,750 unannotated human dialogues and a single negative example. Despite these limitations, we demonstrate competitive performance on four datasets from different domains. Our code, including our metric and experiments, is open sourced.
* In Proceedings of the 4th Workshop on NLP for Conversational AI,
pages 166-183, Dublin, Ireland. Association for Computational Linguistics.
May 2022 * 18 pages, 7 figures
View paper on
 OpenReview
OpenReview