 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrence to the Rescue: Towards Causal Spatiotemporal Representations
Paper and Code
Nov 17, 2018
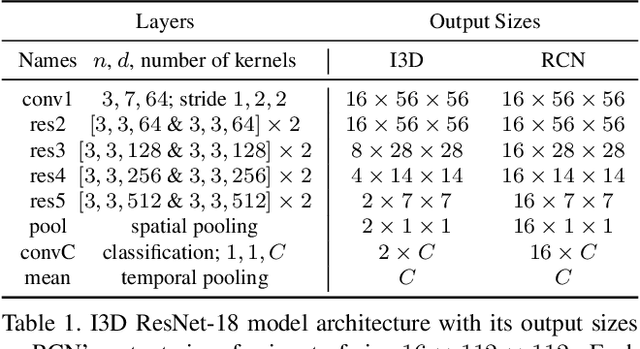


Recently, three dimensional (3D) convolutional neural networks (CNNs) have emerged as dominant methods to capture spatiotemporal representations, by adding to pre-existing 2D CNNs a third, temporal dimension. Such 3D CNNs, however, are anti-causal (i.e., they exploit information from both the past and the future to produce feature representations, thus preventing their use in online settings), constrain the temporal reasoning horizon to the size of the temporal convolution kernel, and are not temporal resolution-preserving for video sequence-to-sequence modelling, as, e.g., in spatiotemporal action detection. To address these serious limitations, we present a new architecture for the causal/online spatiotemporal representation of videos. Namely, we propose a recurrent convolutional network (RCN), which relies on recurrence to capture the temporal context across frames at every level of network depth. Our network decomposes 3D convolutions into (1) a 2D spatial convolution component, and (2) an additional hidden state $1\times 1$ convolution applied across time. The hidden state at any time $t$ is assumed to depend on the hidden state at $t-1$ and on the current output of the spatial convolution component. As a result, the proposed network: (i) provides flexible temporal reasoning, (ii) produces causal outputs, and (iii) preserves temporal resolution. Our experiments on the large-scale large "Kinetics" dataset show that the proposed method achieves superior performance compared to 3D CNNs, while being causal and using fewer parameters.