 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Clustering Algorithm Based on Predefined Level-of-Similarity
Paper and Code
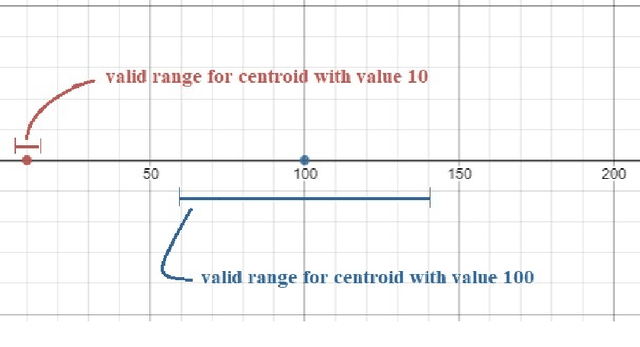
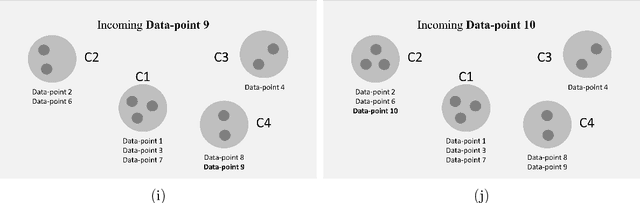
This paper proposes a centroid-based clustering algorithm which is capable of clustering data-points with n-features in real-time, without having to specify the number of clusters to be formed. We present the core logic behind the algorithm, a similarity measure, which collectively decides whether to assign an incoming data-point to a pre-existing cluster, or create a new cluster & assign the data-point to it. The implementation of the proposed algorithm clearly demonstrates how efficiently a data-point with high dimensionality of features is assigned to an appropriate cluster with minimal operations. The proposed algorithm is very application specific and is applicable when the need is perform clustering analysis of real-time data-points, where the similarity measure between an incoming data-point and the cluster to which the data-point is to be associated with, is greater than predefined Level-of-Similarity.